Majoritary Reasons
Let $f$ be a Boolean function represented by a random forest $RF$, $x$ be an instance and $1$ (resp. $0$) the prediction of $RF$ on $x$ ($f(x) = 1$ (resp $f(x)=0$)). A majoritary reason for $x$ is a term $t$ covering $x$, such that $t$ is an implicant of at least a majoritary of decision trees $T_i$ that is minimal w.r.t. set inclusion.
In general, the notions of majoritary reason and of sufficient reason do not coincide. Indeed, a sufficient reason is a prime implicant (covering $x$) of the forest $F$, while a majoritary reason is an implicant $t$ (covering $x$) of a majority of decision trees in the forest $F$. More information about majoritary reasons can be found in the article Trading Complexity for Sparsity in Random Forest Explanations.
The function majoritary_reason allows computing this kind of explanation.
The library also provides a way to check that a reason is majoritary using the function is_majoritary_reason.
Minimal majoritary reason
As for minimal sufficient reasons, a natural way of improving the quality of majoritary reasons is to seek for the most parsimonious ones. A minimal majoritary reason for $x$ is a majoritary reason for $x$ that contains a minimal number of literals. In other words, a minimal majoritary reason has a minimal size.
The function minimal_majoritary_reason allows computing this kind of explanation.
Preferred reasons
One can also find preferred majoritary reasons. Indeed, the user may prefer reason containing some features and can provide weights in order to select some reasons instead of others. Please take a look to the Preferences page for more information on preference handling.
The function preferred_majoritary_reason allows computing this kind of explanation.
Example from Hand-Crafted Trees
For this example, we take the Random Forest of the Building Models page consisting of 4 binary features (𝑥1, 𝑥2, 𝑥3 and 𝑥4).
The following figure shows in red and bold a minimal majoritary reason $(x_2, x_3, x_4)$ for the instance $(1,1,1,1)$. 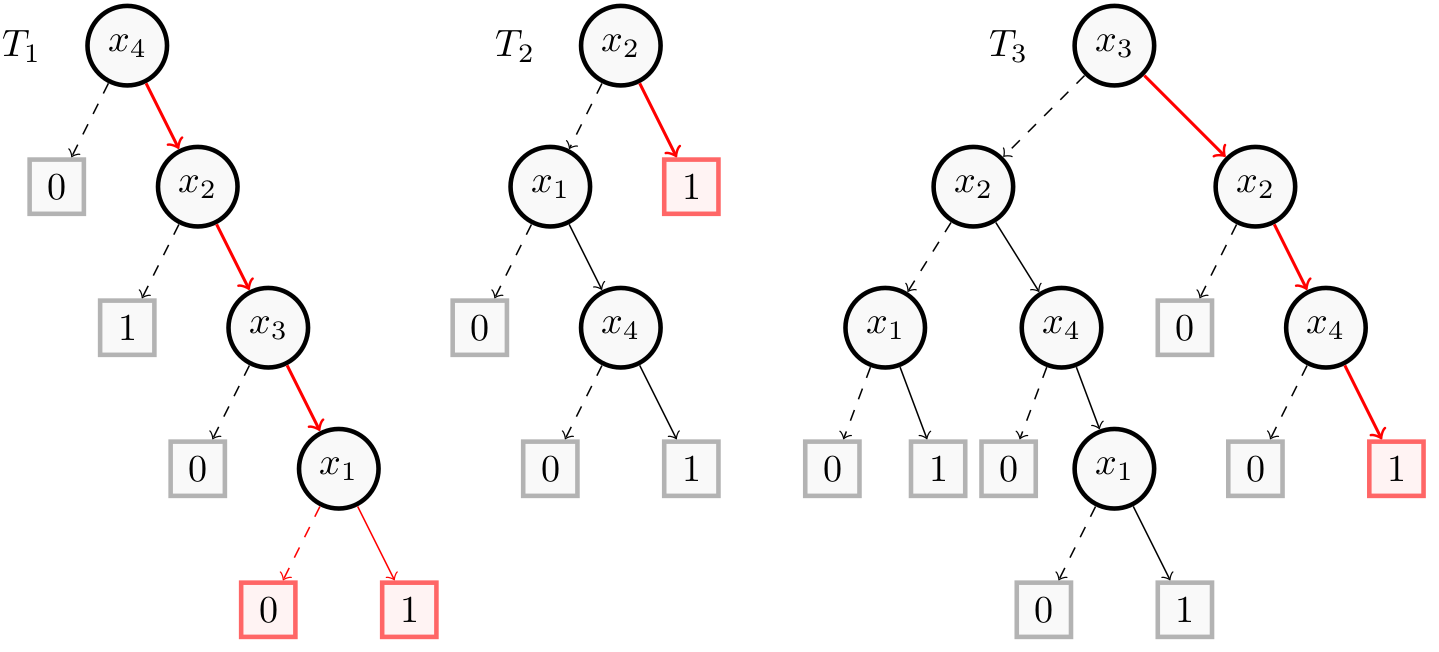
For the majoritary reason $(x_2, x_3, x_4)$, we can see that even if $T_1$ leads to a prediction equal to 0 (when we have $-x_1$), there is always a majority of Decision Trees (i.e. $T_2$ and $T_3$) that give a prediction of 1.
The next figure shows in blue and bold a minimal majoritary reason $(x_2, -x_4)$ for the instance $(0,1,0,0)$.
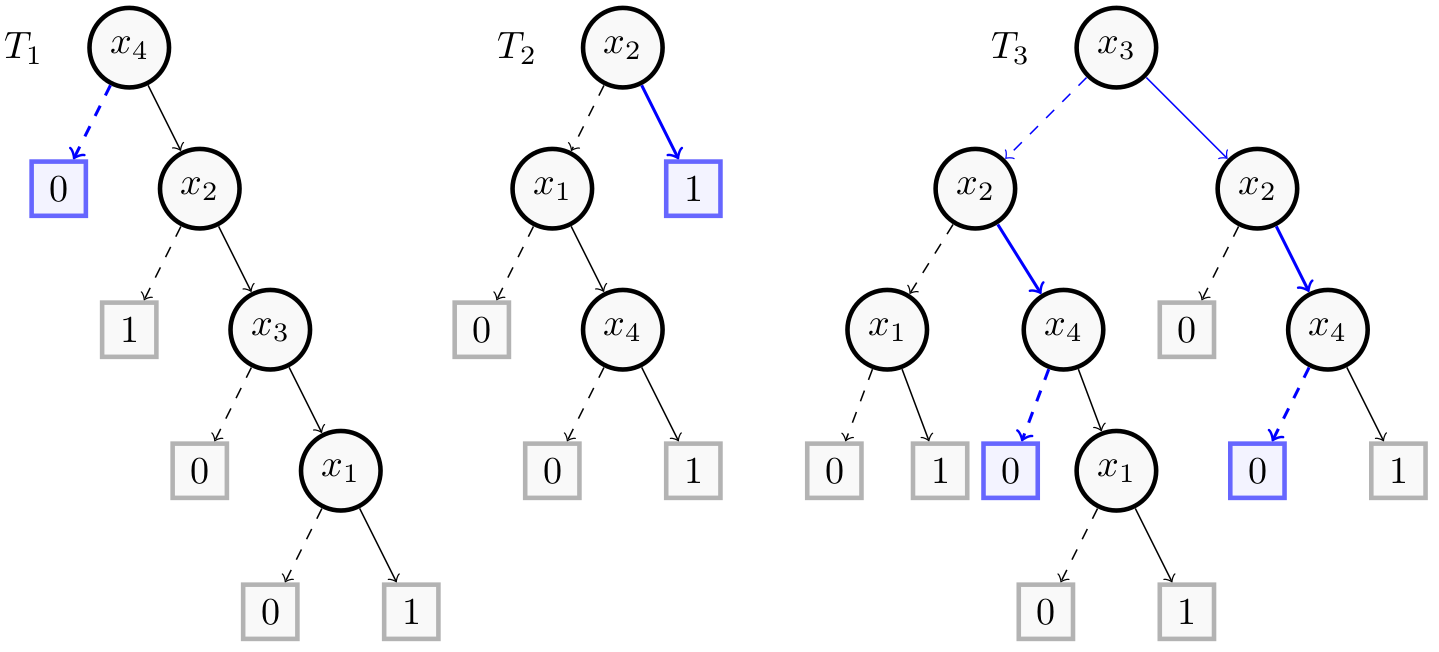
For $(x_2, -x_4)$, $T_2$ always gives a prediction of 1 while $T_1$ and $T_3$ always give a prediction of 0. So in all cases we have a majority of trees ($T_1$ and $T_3$) that lead to the right prediction (0).
Now, we show how to get them with PyXAI. We start by building the random forest:
from pyxai import Builder, Explaining
nodeT1_1 = Builder.DecisionNode(1, left=0, right=1)
nodeT1_3 = Builder.DecisionNode(3, left=0, right=nodeT1_1)
nodeT1_2 = Builder.DecisionNode(2, left=1, right=nodeT1_3)
nodeT1_4 = Builder.DecisionNode(4, left=0, right=nodeT1_2)
tree1 = Builder.DecisionTree(4, nodeT1_4, force_features_equal_to_binaries=True)
nodeT2_4 = Builder.DecisionNode(4, left=0, right=1)
nodeT2_1 = Builder.DecisionNode(1, left=0, right=nodeT2_4)
nodeT2_2 = Builder.DecisionNode(2, left=nodeT2_1, right=1)
tree2 = Builder.DecisionTree(4, nodeT2_2, force_features_equal_to_binaries=True) #4 features but only 3 used
nodeT3_1_1 = Builder.DecisionNode(1, left=0, right=1)
nodeT3_1_2 = Builder.DecisionNode(1, left=0, right=1)
nodeT3_4_1 = Builder.DecisionNode(4, left=0, right=nodeT3_1_1)
nodeT3_4_2 = Builder.DecisionNode(4, left=0, right=1)
nodeT3_2_1 = Builder.DecisionNode(2, left=nodeT3_1_2, right=nodeT3_4_1)
nodeT3_2_2 = Builder.DecisionNode(2, left=0, right=nodeT3_4_2)
nodeT3_3_1 = Builder.DecisionNode(3, left=nodeT3_2_1, right=nodeT3_2_2)
tree3 = Builder.DecisionTree(4, nodeT3_3_1, force_features_equal_to_binaries=True)
forest = Builder.RandomForest([tree1, tree2, tree3], n_classes=2)
We compute a majoritary reason for each of these two instances:
explainer = Explaining.initialize(forest)
explainer.set_instance((1,1,1,1))
majoritary = explainer.majoritary_reason(seed=1234)
print("target_prediction:", explainer.target_prediction)
print("majoritary:", majoritary)
assert explainer.is_majoritary_reason(majoritary)
minimal = explainer.minimal_majoritary_reason()
print("minimal:", minimal)
print("-------------------------------")
instance = (0,1,0,0)
explainer.set_instance(instance)
print("target_prediction:", explainer.target_prediction)
majoritary = explainer.majoritary_reason()
print("majoritary:", majoritary)
minimal = explainer.minimal_majoritary_reason()
print("minimal:", minimal)
target_prediction: 1
majoritary: (1, 2, 4)
[['v', '-1', '2', '3', '4', '-5', '6', '7', '8', '9', '']]
minimal: (2, 3, 4)
-------------------------------
target_prediction: 0
majoritary: (-1, -4)
[['v', '1', '2', '3', '-4', '5', '-6', '7', '-8', '9', '']]
minimal: (2, -4)
Example from a Real Dataset
For this example, we take the compas dataset. We create a model using the hold-out approach (by default, the test size is set to 30%) and select a well-classified instance.
from pyxai import Learning, Explaining
learner = Learning.Scikitlearn("../../../dataset/compas.csv", problem_type='classification')
model = learner.evaluate(splitting_method=Learning.HOLD_OUT, model_type=Learning.RF)
instance, prediction = learner.get_instances(model, n=1, is_correct=True)
-------------- Information ---------------
Problem type: classification
Instances type: tabular
Labels type: classes
Dataset path: ../../../dataset/compas.csv
nFeatures (nAttributes, with the labels): 11
nInstances (nObservations): 6172
nLabels: 2
--------------- Model creation, fitting and evaluation ---------------
Splitting method: hold-out
Problem type: classification
Models type: random-forest
model_parameters: {}
--------- Evaluation Information ---------
For the evaluation number 0:
Metrics:
sklearn_confusion_matrix: [[595, 216], [321, 411]]
precision: 65.55023923444976
recall: 56.14754098360656
f1_score: 60.48565121412804
specificity: 73.36621454993835
true_positive: 411
true_negative: 595
false_positive: 216
false_negative: 321
accuracy: 65.19766688269605
Number of Training instances: 4629
Number of Testing instances: 1543
--------------- Explainer ----------------
For the split number 0:
**Random Forest Model**
nClasses: 2
nTrees: 100
nVariables: 69
--------------- Instances ----------------
Number of instances selected: 1
----------------------------------------------
We compute a majoritary reason for the instance and a minimal one.
explainer = Explaining.initialize(model, instance)
print("instance:", instance)
print("prediction:", prediction)
print()
majoritary_reason = explainer.majoritary_reason()
#for s in sufficient_reasons:
print("\nmajoritary reason:", majoritary_reason)
print("len majoritary reason:", len(majoritary_reason))
print("to features", explainer.to_features(majoritary_reason))
print("is majoritary reason: ", explainer.is_majoritary_reason(majoritary_reason))
print()
minimal = explainer.minimal_majoritary_reason()
print("\nminimal:", minimal)
print("minimal:", len(minimal))
print("to features", explainer.to_features(majoritary_reason))
print("is majoritary reason: ", explainer.is_majoritary_reason(majoritary_reason))
instance: Misdemeanor 0
Number_of_Priors 0
score_factor 0
Age_Above_FourtyFive 1
Age_Below_TwentyFive 0
African_American 0
Asian 0
Hispanic 0
Native_American 0
Other 1
Female 0
Name: 0, dtype: int64
prediction: 0
majoritary reason: (-2, 4, -5, -6, 7, -10, -11, -14, -15, -17, -29)
len majoritary reason: 11
to features ['Number_of_Priors <= 0.5', 'score_factor <= 0.5', 'Age_Above_FourtyFive > 0.5', 'Age_Below_TwentyFive <= 0.5', 'African_American <= 0.5', 'Other > 0.5', 'Female <= 0.5']
is majoritary reason: True
minimal: (-1, -2, -3, 4, -5, -8, -10, -11, -15, -17)
minimal: 10
to features ['Number_of_Priors <= 0.5', 'score_factor <= 0.5', 'Age_Above_FourtyFive > 0.5', 'Age_Below_TwentyFive <= 0.5', 'African_American <= 0.5', 'Other > 0.5', 'Female <= 0.5']
is majoritary reason: True
Other types of explanations are presented in the Explanations Computation page.