Tree-Specific Explanations
Let $BT$ be a Boosted Tree composed of {$T_1,\ldots T_n$} regression trees and $x$ be an instance.
- A worst instance extending $t$ given $F$ is an instance $x’$ such that $t \subseteq t_{x’}$ and: \(x' = \mathit{argmin}_{x'': t \subseteq t_{x''}}(\{w(F, x'')\})\)
- A best instance extending $t$ given $F$ is an instance $x’$ such that $t \subseteq t_{x’}$ and: \(x' = \mathit{argmax}_{x'': t \subseteq t_{x''}}(\{w(F, x'')\})\)
$W(t, F)$ (resp. $B(t, F)$) denotes the set of worst (resp. best) instances covered by $t$ given $F$, and $w_\downarrow(t, F)$ (resp. $w_\uparrow(t, F)$) denotes the weight of the worst (resp. best) instance covered by $t$ given $F$. For example, for the sufficient reason $t$ = ($A_1 > 2$, $A_4 = 1$) for the instance $x$ = ($A_1=4$, $A_2 = 3$, $A_3 = 1$, $A_4 = 1$) of the sufficient reason page, a worst instance can be $x’$ = ($A_1=4$, $A_2 = 1$, $A_3 = 1$, $A_4 = 1$) with $w(F, x’) = 0.3$ . Identifying a worst (resp. best) instance $x$ for given a boosted tree is intractable. Interestingly, when the classifier consists of a regression tree, identifying an element of $W(t, T)$ (resp. $B(t, T)$) for a tree $T$ is easy.
We are now ready to define the notion of tree-specific explanation $t$ for an instance $x$ given a boosted tree $BT$. We start with the binary case, i.e., when $BT$ consists of a single forest $F$:
- If $BT(x) = 1$, then $t$ is a tree-specific explanation for $x$ given $F$ if and only if $t$ is a subset of $t_{x}$ such that $\sum_{k=1}^p w_\downarrow(t, T_k) > 0$ and no proper subset of $t$ satisfies the latter condition.
- If $BT(x) = 0$, then $t$ is a tree-specific explanation for $x$ given $F$ if and only if $t$ is a subset of $t_{x}$ such that $\sum_{k=1}^p w_\uparrow(t, T_k) \leq 0$ and no proper subset of $t$ satisfies the latter condition.
More generally, in the multi-class setting, TS-explanations can be defined as follows:
Let $BT = {F^1,\cdots, F^{m}}$ be a boosted tree over ${A_1, \ldots, A_n}$ where each $F^j$ ($j \in [m]$) contains $p_j$ trees, and $x$ such that $BT(x) = i$. Conceptually, $t$ is a tree-specific explanation for $x$ given $BT$ if and only if $t$ is a subset of $t_{x}$ such that for every $j \in [m] \setminus {i}$, we have $\sum_{k=1}^{p_i} w_\downarrow(t, T_k^i) > \sum_{k=1}^{p_j} w_\uparrow(t, T_k^j)$, and no proper subset of $t$ satisfies the latter condition.
In general, the notions of tree-specific explanation and of sufficient reason do not coincide. Indeed, a sufficient reason is a prime implicant (covering $x$) of the Boosted Tree $BT$, while a tree-specific explanation is an implicant $t$ (covering $x$). Since there is a simple, linear-time algorithm for computing $w_\downarrow(t, F)$ and $w_\uparrow(t, F)$ and for deriving a worst-case and a best-case instance, the tree-specific explanations for $x$ are much easier to compute than the sufficient reasons and remain abductive.
More information about tree-specific explanations can be found in the paper Computing Abductive Explanations for Boosted Trees.
The function ExplainerBT.tree_specific_reason allows computing this kind of explanation.
The library also provides a way to check that a reason is tree specific using the function is_tree_specific_reason.
A natural way of improving the quality of tree-specific explanations is to seek for the most parsimonious ones. A minimal tree-specific explanation for $x$ is a tree-specific explanation for $x$ that contains a minimal number of literals. In other words, a minimal tree-specific explanation has a minimal size.
The function ExplainerBT.minimal_tree_specific_reasons allows computing this kind of explanation.
The PyXAI library also provides a way to test that an explanation is actually a tree-specific explanation:
Example from Hand-Crafted Trees
For this example, we take the Boosted Tree of the Building Models page.
The next figure represents a Boosted Tree using $4$ features ($A_1$, $A_2$, $A_3$ and $A_4$), where $A_1$ and $A_2$ are numerical, $A_3$ is categorical and $A_4$ is a Boolean. In this figure, we show worst instances and the corresponding weights (in dark red) of the sufficient reason $t$ = ($A_1 = 4$, $A_4 = 1$) for the instance $x$ = ($A_1 = 4$, $A_2 = 3$, $A_3 = 1$, $A_4 = 1$).
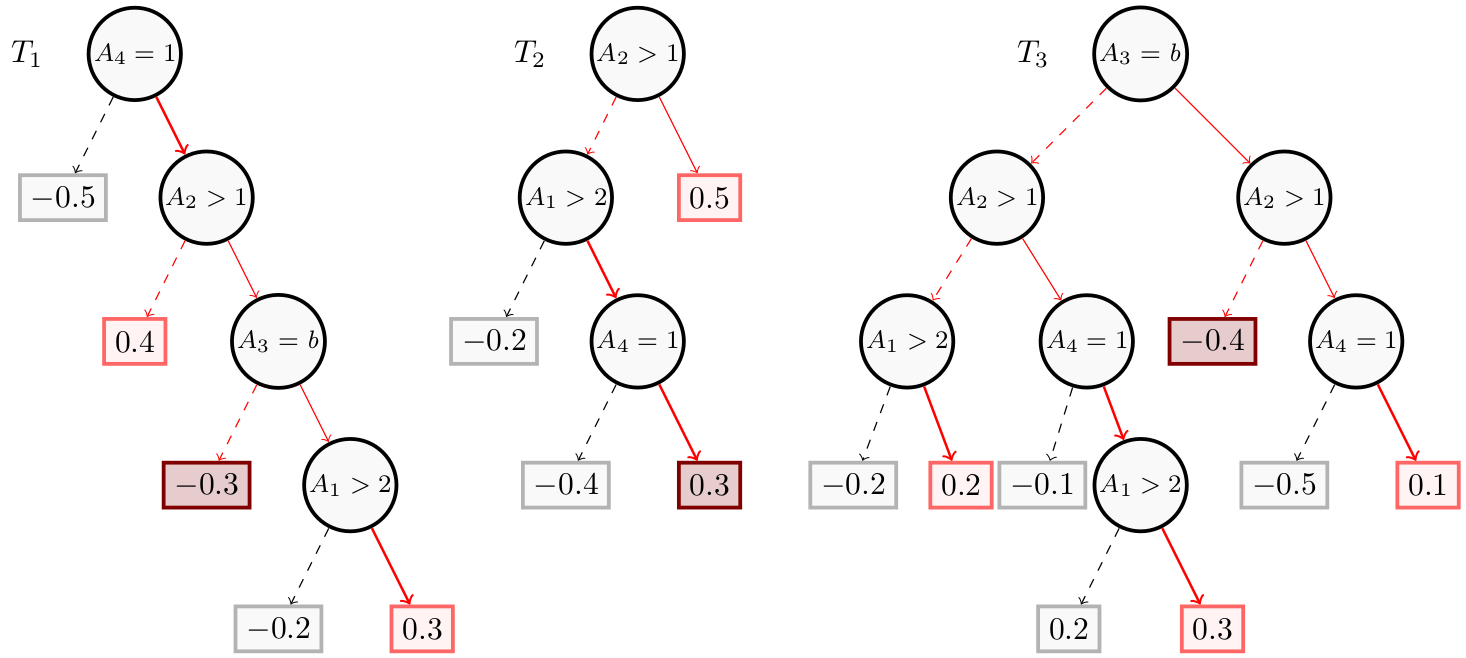
This sufficient reason $t$ = ($A_1 = 4$, $A_4 = 1$) is not a tree-specific explanation for $x$ given $BT$. Indeed, we have $w_\downarrow(t, T_1) = -0.3$, $w_\downarrow(t, T_2) = 0.3$, and $w_\downarrow(t, T_3) = -0.4$, hence $w_\downarrow(t, T_1) + w_\downarrow(t, T_2) + w_\downarrow(t, T_3) = -0.4 < 0$ while $w(F, x) = 0.9 > 0$.
In the next figure, in this figure, $t’ = (A_2 > 1, A_4 = 1)$ is a tree-specific explanation for $x$ given $BT$.
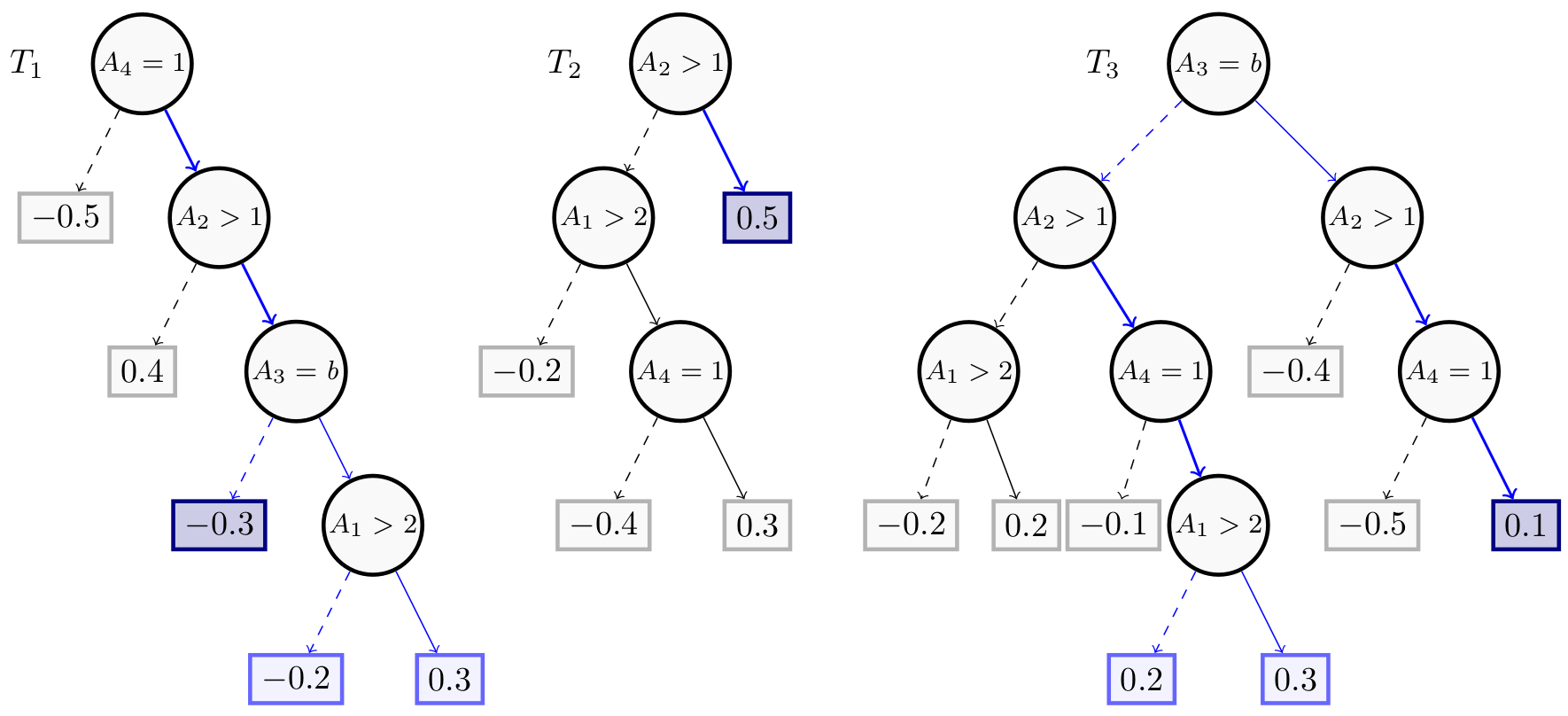
We have $w_\downarrow(t’, T_1) = -0.3$, $w_\downarrow(t’, T_2) = 0.5$, and $w_\downarrow(t’, T_3) = 0.1$, hence $w_\downarrow(t’, T_1) + w_\downarrow(t’, T_2) + w_\downarrow(t’, T_3) = 0.3 > 0$. It can be verified that $t’$ also is a sufficient reason for $x$ given $BT$.
We show now how to get them with PyXAI. We start by building the Boosted Tree:
from pyxai import Builder, Explaining
node1_1 = Builder.DecisionNode(1, operator=Builder.GT, threshold=2, left=-0.2, right=0.3)
node1_2 = Builder.DecisionNode(3, operator=Builder.EQ, threshold=1, left=-0.3, right=node1_1)
node1_3 = Builder.DecisionNode(2, operator=Builder.GT, threshold=1, left=0.4, right=node1_2)
node1_4 = Builder.DecisionNode(4, operator=Builder.EQ, threshold=1, left=-0.5, right=node1_3)
tree1 = Builder.DecisionTree(4, node1_4)
node2_1 = Builder.DecisionNode(4, operator=Builder.EQ, threshold=1, left=-0.4, right=0.3)
node2_2 = Builder.DecisionNode(1, operator=Builder.GT, threshold=2, left=-0.2, right=node2_1)
node2_3 = Builder.DecisionNode(2, operator=Builder.GT, threshold=1, left=node2_2, right=0.5)
tree2 = Builder.DecisionTree(4, node2_3)
node3_1 = Builder.DecisionNode(1, operator=Builder.GT, threshold=2, left=0.2, right=0.3)
node3_2_1 = Builder.DecisionNode(1, operator=Builder.GT, threshold=2, left=-0.2, right=0.2)
node3_2_2 = Builder.DecisionNode(4, operator=Builder.EQ, threshold=1, left=-0.1, right=node3_1)
node3_2_3 = Builder.DecisionNode(4, operator=Builder.EQ, threshold=1, left=-0.5, right=0.1)
node3_3_1 = Builder.DecisionNode(2, operator=Builder.GT, threshold=1, left=node3_2_1, right=node3_2_2)
node3_3_2 = Builder.DecisionNode(2, operator=Builder.GT, threshold=1, left=-0.4, right=node3_2_3)
node3_4 = Builder.DecisionNode(3, operator=Builder.EQ, threshold=1, left=node3_3_1, right=node3_3_2)
tree3 = Builder.DecisionTree(4, node3_4)
BT = Builder.BoostedTrees([tree1, tree2, tree3], n_classes=2)
We compute a tree-specific explanation for this instance:
explainer = Explaining.initialize(BT)
explainer.set_instance((4,3,2,1))
tree_specific = explainer.tree_specific_reason()
print("target_prediction:", explainer.target_prediction)
print("tree specific:", tree_specific)
assert explainer.is_tree_specific_reason(tree_specific)
minimal = explainer.minimal_tree_specific_reasons(n=1)
print("minimal:", minimal)
target_prediction: 1
tree specific: (1, 2)
minimal: (1, 2)
Example from a Real Dataset
For this example, we take the compas.csv dataset. We create a model using the hold-out approach (by default, the test size is set to 30%) and select a well-classified instance.
from pyxai import Learning, Explaining
learner = Learning.Xgboost("../../../dataset/compas.csv", problem_type='classification')
model = learner.evaluate(splitting_method=Learning.HOLD_OUT, model_type=Learning.BT)
instance, prediction = learner.get_instances(model, n=1, is_correct=True)
-------------- Information ---------------
Problem type: classification
Instances type: tabular
Labels type: classes
Dataset path: ../../../dataset/compas.csv
nFeatures (nAttributes, with the labels): 11
nInstances (nObservations): 6172
nLabels: 2
--------------- Model creation, fitting and evaluation ---------------
Splitting method: hold-out
Problem type: classification
Models type: boosted-tree
model_parameters: {}
--------- Evaluation Information ---------
For the evaluation number 0:
Metrics:
sklearn_confusion_matrix: [[634, 196], [287, 426]]
precision: 68.48874598070739
recall: 59.74754558204769
f1_score: 63.820224719101134
specificity: 76.3855421686747
true_positive: 426
true_negative: 634
false_positive: 196
false_negative: 287
accuracy: 68.69734283862606
Number of Training instances: 4629
Number of Testing instances: 1543
--------------- Explainer ----------------
For the split number 0:
**Boosted Tree model**
NClasses: 2
nTrees: 100
nVariables: 38
--------------- Instances ----------------
Number of instances selected: 1
----------------------------------------------
We compute a tree-specific explanation and a minimal one. Since finding a minimal one explanation is time consuming, we set a time limit. In the case of the time limit is reached, we may obtain only an approximation of a minimal explanation.
explainer = Explaining.initialize(model, instance)
print("instance:", instance)
print("prediction:", prediction)
print()
tree_specific_reason = explainer.tree_specific_reason()
#for s in sufficient_reasons:
print("\ntree specific reason:", tree_specific_reason)
print("len tree specific reason:", len(tree_specific_reason))
print("to features", explainer.to_features(tree_specific_reason))
print("is tree specific reason: ", explainer.is_tree_specific_reason(tree_specific_reason))
print()
minimal = explainer.minimal_tree_specific_reasons(time_limit=5)
print("\nminimal:", minimal)
print("minimal:", len(minimal))
print("to features", explainer.to_features(tree_specific_reason))
print("is majoritary reason: ", explainer.is_tree_specific_reason(tree_specific_reason))
if explainer.elapsed_time == Explaining.TIMEOUT:
print("time out... It is an approximation")
instance: Misdemeanor 0
Number_of_Priors 0
score_factor 0
Age_Above_FourtyFive 1
Age_Below_TwentyFive 0
African_American 0
Asian 0
Hispanic 0
Native_American 0
Other 1
Female 0
Name: 0, dtype: int64
prediction: 0
tree specific reason: (-1, -2, -3, -4, 5, 6, -7, -8, -9, -10, -11, -13, -14, -15, -17, -18, -19, -20, -21, -22, -23, -24, -25, -26, -27, -28, -33, -37)
len tree specific reason: 28
to features ['Number_of_Priors < 1.0', 'score_factor < 1.0', 'Age_Above_FourtyFive >= 1.0', 'Age_Below_TwentyFive < 1.0', 'African_American < 1.0', 'Asian < 1.0', 'Hispanic < 1.0', 'Other >= 1.0', 'Female < 1.0']
is tree specific reason: True
minimal: ((-1, -2, -3, -4, 5, -7, -8, -10, -11, -13, -15, -17, -18, -19, -20, -21, -22, -23, -24, -25, -26, -27, -28, -29, -33, -37, -38), (-1, -2, -3, -4, 5, -7, -8, -10, -11, -13, -15, -17, -18, -19, -20, -21, -22, -23, -24, -25, -26, -27, -28, -29, -33, -34, -37), (-1, -2, -3, -4, 5, -7, -8, -10, -11, -13, -14, -15, -17, -18, -19, -20, -21, -22, -23, -24, -25, -26, -27, -28, -29, -33, -37))
minimal: 3
to features ['Number_of_Priors < 1.0', 'score_factor < 1.0', 'Age_Above_FourtyFive >= 1.0', 'Age_Below_TwentyFive < 1.0', 'African_American < 1.0', 'Asian < 1.0', 'Hispanic < 1.0', 'Other >= 1.0', 'Female < 1.0']
is majoritary reason: True
Other types of explanations are presented in the Explanations Computation page.