Rectification for Decision Trees
Further information on the rectification method for Decision Trees is available in the paper Rectifying Binary Classifiers.
Example from a Hand-Crafted Tree
To illustrate this, we take an example of a credit scoring scenario.
Each customer is characterized by:
- an annual income $I$ (in k\$),
- the fact of having already reimbursed a previous loan ($R$),
- and, whether or not, the customer has a permanent position ($PP$).
A decision tree T representing the model is described in the following figure. The Boolean conditions used in $T$ are $I > 30$, $I > 20$, $R$, and $PP$.
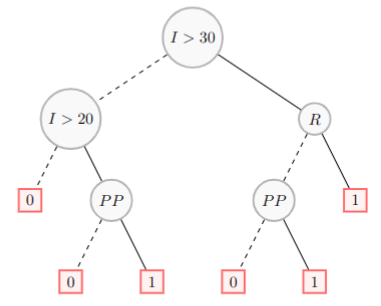
We start by building the decision tree:
from pyxai import Builder, Explaining
node_L_1 = Builder.DecisionNode(3, operator=Builder.EQ, threshold=1, left=0, right=1)
node_L_2 = Builder.DecisionNode(1, operator=Builder.GT, threshold=20, left=0, right=node_L_1)
node_R_1 = Builder.DecisionNode(3, operator=Builder.EQ, threshold=1, left=0, right=1)
node_R_2 = Builder.DecisionNode(2, operator=Builder.EQ, threshold=1, left=node_R_1, right=1)
root = Builder.DecisionNode(1, operator=Builder.GT, threshold=30, left=node_L_2, right=node_R_2)
tree = Builder.DecisionTree(3, root, feature_names=["I", "PP", "R"])
Consider the instance $x = (I = 25, R = 1, PP = 1)$ corresponding to a customer applying for a loan. We initialize the explainer with this instance and the associated theory (see the Theories page for more information).
loan_types = {
"numerical": ["I"],
"binary": ["PP", "R"],
}
explainer = Explaining.initialize(tree, instance=(25, 1, 1), features_type=loan_types)
print("binary representation: ", explainer.binary_representation)
print("target_prediction:", explainer.target_prediction)
print("to_features:", explainer.to_features(explainer.binary_representation, eliminate_redundant_features=False))
feature_names: ['I', 'PP', 'R']
--------- Theory Feature Types -----------
Before the one-hot encoding of categorical features:
Numerical features: 1
Categorical features: 0
Binary features: 2
Number of features: 3
Characteristics of categorical features: {}
Number of used features in the model (before the encoding of categorical features): 3
Number of used features in the model (after the encoding of categorical features): 3
----------------------------------------------
binary representation: (-1, 2, 3, 4)
target_prediction: 1
to_features: ['I <= 30', 'I > 20', 'PP == 1', 'R == 1']
The user (a bank employee) disagrees with this prediction (the loan acceptance). For him/her, the following classification rule must be obeyed: whenever the annual income of the client is lower than 30, the demand should be rejected. To do this rectification, we use the rectify() method of the explainer object. More information about this method are available on the Rectification page.
rectified_model = explainer.rectify(conditions=(-1, ), label=0)
# Keep in mind that the condition (-1, ) means that 'I <= 30'.
print("target_prediction:", explainer.target_prediction)
Rectify - Number of nodes - Initial (c++): 11
Rectify - Number of nodes - After rectification (c++): 11
Rectify - Number of nodes - After simplification with the theory (c++): 11
Rectify - Number of nodes - After elimination of redundant nodes (c++): 7
Rectify - Number of nodes - Final (c++): 7
Rectification time: 0.00039471000000013134
--------------
target_prediction: 0
Here is the model without any simplification:
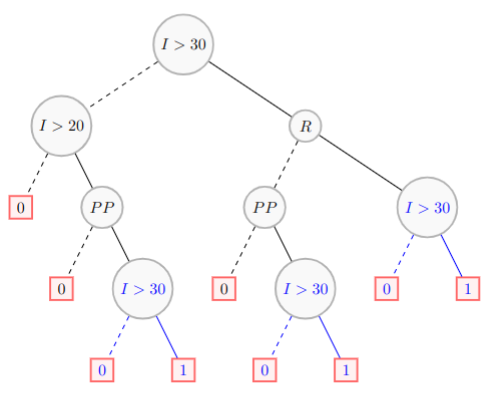
Here is the model once simplified:
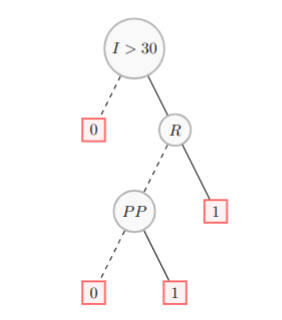
We can check that the instance is now correctly classified:
print("target_prediction:", rectified_model.predict_instance((25, 1, 1)))
target_prediction: 0
Example from a Real Dataset
For this example, we take the compas.csv dataset. We create a model using the hold-out approach (by default, the test size is set to 30%) and select a misclassified instance.
from pyxai import Learning, Explaining
learner = Learning.Scikitlearn("../dataset/compas.csv", problem_type='classification')
model = learner.evaluate(splitting_method=Learning.HOLD_OUT, model_type=Learning.DT, splitting_parameters={'random_state':0})
dict_information = learner.get_instances(model, n=1, indexes=Learning.TEST, is_correct=False, details=True, seed=2)
instance = dict_information["instance"]
print(instance)
label = dict_information["label"]
prediction = dict_information["prediction"]
-------------- Information ---------------
Problem type: classification
Instances type: tabular
Labels type: classes
Dataset path: ../dataset/compas.csv
nFeatures (nAttributes, with the labels): 11
nInstances (nObservations): 6172
nLabels: 2
--------------- Model creation, fitting and evaluation ---------------
Splitting method: hold-out
Problem type: classification
Models type: decision-tree
model_parameters: {}
--------- Evaluation Information ---------
For the evaluation number 0:
Metrics:
sklearn_confusion_matrix: [[663, 189], [342, 349]]
precision: 64.86988847583643
recall: 50.50651230101303
f1_score: 56.794141578519124
specificity: 77.8169014084507
true_positive: 349
true_negative: 663
false_positive: 189
false_negative: 342
accuracy: 65.58651976668827
Number of Training instances: 4629
Number of Testing instances: 1543
--------------- Explainer ----------------
For the split number 0:
**Decision Tree Model**
nFeatures: 11
nNodes: 556
nVariables: 45
--------------- Instances ----------------
Number of instances selected: 1
----------------------------------------------
Misdemeanor 0
Number_of_Priors 1
score_factor 1
Age_Above_FourtyFive 0
Age_Below_TwentyFive 1
African_American 0
Asian 0
Hispanic 0
Native_American 0
Other 0
Female 0
Name: 3367, dtype: int64
We activate the explainer with the associated theory and the selected instance:
compas_types = {
"numerical": ["Number_of_Priors"],
"binary": ["Misdemeanor", "score_factor", "Female"],
"categorical": {"{African_American,Asian,Hispanic,Native_American,Other}": ["African_American", "Asian", "Hispanic", "Native_American", "Other"],
"Age*": ["Above_FourtyFive", "Below_TwentyFive"]}
}
explainer = Explaining.initialize(model, instance=instance, features_type=compas_types)
feature_names: ['Misdemeanor', 'Number_of_Priors', 'score_factor', 'Age_Above_FourtyFive', 'Age_Below_TwentyFive', 'African_American', 'Asian', 'Hispanic', 'Native_American', 'Other', 'Female']
--------- Theory Feature Types -----------
Before the one-hot encoding of categorical features:
Numerical features: 1
Categorical features: 2
Binary features: 3
Number of features: 6
Characteristics of categorical features: {'African_American': ['{African_American,Asian,Hispanic,Native_American,Other}', 'African_American', ['African_American', 'Asian', 'Hispanic', 'Native_American', 'Other']], 'Asian': ['{African_American,Asian,Hispanic,Native_American,Other}', 'Asian', ['African_American', 'Asian', 'Hispanic', 'Native_American', 'Other']], 'Hispanic': ['{African_American,Asian,Hispanic,Native_American,Other}', 'Hispanic', ['African_American', 'Asian', 'Hispanic', 'Native_American', 'Other']], 'Native_American': ['{African_American,Asian,Hispanic,Native_American,Other}', 'Native_American', ['African_American', 'Asian', 'Hispanic', 'Native_American', 'Other']], 'Other': ['{African_American,Asian,Hispanic,Native_American,Other}', 'Other', ['African_American', 'Asian', 'Hispanic', 'Native_American', 'Other']], 'Age_Above_FourtyFive': ['Age', 'Above_FourtyFive', ['Above_FourtyFive', 'Below_TwentyFive']], 'Age_Below_TwentyFive': ['Age', 'Below_TwentyFive', ['Above_FourtyFive', 'Below_TwentyFive']]}
Number of used features in the model (before the encoding of categorical features): 6
Number of used features in the model (after the encoding of categorical features): 11
----------------------------------------------
We compute why the model gives the prediction one for this instance:
print("current prediction: ", explainer.target_prediction)
reason = explainer.sufficient_reason(n=1)
print("explanation:", reason)
#print("to_features:", explainer.to_features(reason))
current prediction: 1
explanation: (1, 4, 5, -10, -12, -13)
Suppose that the user knows that every instance covered by the explanation (-1, -2, -3, -4) should be classified as a negative instance. The model must be rectified by the corresponding classification rule. Once the model has been corrected, the instance is classified as expected by the user:
model = explainer.rectify(conditions=reason, label=0) # We want to change the prediction
print("new prediction:", explainer.target_prediction)
Rectify - Number of nodes - Initial (c++): 1113
Rectify - Number of nodes - After rectification (c++): 1113
Rectify - Number of nodes - After simplification with the theory (c++): 1113
Rectify - Number of nodes - After elimination of redundant nodes (c++): 665
Rectify - Number of nodes - Final (c++): 665
Rectification time: 0.008641170999998948
--------------
new prediction: 0