Quick Start
Once pyxai has been installed, you can use these commands:
python3 <file.py>: Execute a python file with lines of code using PyXAI
python3 -m pyxai -gui: Open the PyXAI’s Graphical User Interface
python3 -m pyxai -explanations: Copy the explanations backups of GUI in your current directory
python3 -m pyxai -examples: Copy the examples in your current directory
Let us give a quick illustration of PyXAI, showing how to compute explanations given a ML model. 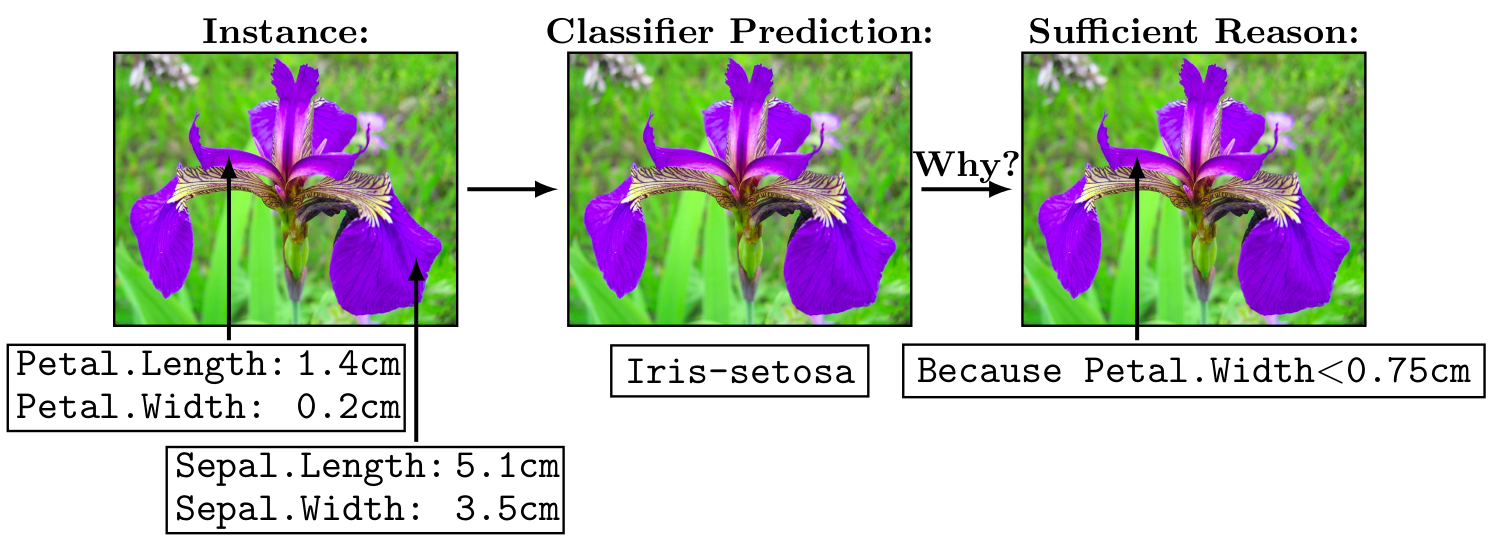
The first thing to do is to import the components of PyXAI. In order to import only the necessary methods into a project, PyXAI is composed of three distinct modules: Learning, Explainer, and Tools.
from pyxai import Learning, Explainer, Tools
If you encounter a problem, this is certainly because you need the python package PyXAI to be installed on your system. You need to execute a command like python3 -m pip install pyxai. See the Installation page for details.
In most situations, the use of PyXAI library requires to achieve two successive steps: first the generation of an ML model from a dataset (with the Learning module) and second, given the learned model, the computation of explanations for some instances (using the Explainer module).
Machine Learning
For this example, we want to create a decision tree classifier for the iris dataset using Scikit-learn.
learner = Learning.Scikitlearn("../dataset/iris.csv", learner_type=Learning.CLASSIFICATION)
data:
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 Iris-virginica
146 6.3 2.5 5.0 1.9 Iris-virginica
147 6.5 3.0 5.2 2.0 Iris-virginica
148 6.2 3.4 5.4 2.3 Iris-virginica
149 5.9 3.0 5.1 1.8 Iris-virginica
[150 rows x 5 columns]
-------------- Information ---------------
Dataset name: ../dataset/iris.csv
nFeatures (nAttributes, with the labels): 5
nInstances (nObservations): 150
nLabels: 3
It is possible to download this dataset from the UCI Machine Learning Repository – Iris Data Set or here. In our case, it is located in the directory ../dataset. The parameter learner_type=Learning.CLASSIFICATION asks to achieve a classification task. The Iris Dataset contains four features (length and width of sepals and petals) of 50 samples of three species of Iris (Iris setosa, Iris virginica and Iris versicolor). The goal of the classifier is to find the right outcome for an instance among three classes: setosa, virginica, versicolor.
To create models, PyXAI implements methods to directly run an ML experimental protocol (with the train-test split technique). Several cross-validation methods (Learning.HOLD_OUT, Learning.K_FOLDS, Learning.LEAVE_ONE_GROUP_OUT) and models (Learning.DT, Learning.RF, Learning.BT) are available.
In this example, we compute a Decision Tree (see the parameter output=Learning.DT).
model = learner.evaluate(method=Learning.HOLD_OUT, output=Learning.DT)
--------------- Evaluation ---------------
method: HoldOut
output: DT
learner_type: Classification
learner_options: {'max_depth': None, 'random_state': 0}
--------- Evaluation Information ---------
For the evaluation number 0:
metrics:
accuracy: 97.77777777777777
nTraining instances: 105
nTest instances: 45
--------------- Explainer ----------------
For the evaluation number 0:
**Decision Tree Model**
nFeatures: 4
nNodes: 6
nVariables: 5
Once the model is created, we select an instance in order to be able to derive explanations. Here, a well-classified instance is chosen: the model predicts the first class 0 (i.e. the Iris setosa class) thanks to the correct=True and the predictions=[0] parameters.
instance, prediction = learner.get_instances(model, n=1, correct=True, predictions=[0])
--------------- Instances ----------------
number of instances selected: 1
----------------------------------------------
Please consult the Learning page for more details about this ML part.
Explainer
The Explainer module contains different methods to generate explanations. In this purpose, the model and the target instance are defined as parameters of the initialize function of this module.
explainer = Explainer.initialize(model, instance)
The initialize function converts the instance into binary variables (called a binary representation) coding the associated model. More precisely, each of these binary variables represents a condition (feature $op$ value ?) in the model where $op$ is a standard comparison operator. Scikit-learn and XGBoost use the operator $\ge$. With respect to the instance, the sign of a binary variable indicates whether the condition is true or not in the model. Here, we can see the instance and its binary representation. We can see the conditions related to the binary representation using the function to_features which is explained below.
print("instance:", instance)
print("binary representation:", explainer.binary_representation)
print("conditions related to the binary representation:", explainer.to_features(explainer.binary_representation,eliminate_redundant_features=False))
instance: [5.1 3.5 1.4 0.2]
binary representation: (-1, -2, -3, 4, -5)
conditions related to the binary representation: ('Sepal.Width > 3.100000023841858', 'Petal.Length <= 4.950000047683716', 'Petal.Width <= 0.75', 'Petal.Width <= 1.6500000357627869', 'Petal.Width <= 1.75')
We notice that the binary representation of this instance contains more than 4 variables because the decision tree of the model is composed of five nodes (binary variables). Indeed, the feature Petal.Width appears 3 times whereas Sepal.Length is useless. Please see the concepts page for more information on binary representations.
Abductive explanations
In PyXAI, several types of explanation are available. In their binary forms representing conditions, these are called reasons. In our example, we choose to compute one of the most popular type of explanations: a sufficient reason. A sufficient reason is an abductive explanation (any other instance X’ sharing the conditions of this reason is classified by the model as X is) for which no proper subset of this reason is a sufficient reason (i.e., the explanation is minimal with respect to set inclusion).
sufficient_reason = explainer.sufficient_reason(n=1)
print("sufficient_reason:", sufficient_reason)
sufficient_reason: (-1,)
We can get the features involved in the reason thanks to the method to_features:
print("to_features:", explainer.to_features(sufficient_reason))
to_features: ('Petal.Width <= 0.75',)
The to_features method eliminates redundant features by default and is also able to return more information about the features using the details parameter. This method is described in the concepts page.
We can check whether the derived explanation actually is a reason.
print("is sufficient: ", explainer.is_sufficient_reason(sufficient_reason))
is sufficient: True
It is important to note that computing and checking reasons are done independently.
To conclude, the sufficient reason (('Petal.Width < 0.75',)) explains why the instance [5.1 3.5 1.4 0.2] is well classified by the model (the prediction was Iris-setosa). It is because the fourth feature (the petal width in cm), set to 0.2 cm, is not greater or equal than 0.75 cm (see the attached image).
Contrastive explanations
Now, let us consider another instance, a wrongly classified one using the parameter correct=False of the function get_instance. We set this instance to the explainer with the set_instance method.
instance, prediction = learner.get_instances(model, n=1, correct=False)
explainer.set_instance(instance)
--------------- Instances ----------------
number of instances selected: 1
----------------------------------------------
We can explain why this instance is not classified differently by providing a contrastive explanation.
contrastive_reason = explainer.contrastive_reason()
print("contrastive reason", contrastive_reason)
print("to_features:", explainer.to_features(contrastive_reason, contrastive=True))
contrastive reason (1,)
to_features: ('Petal.Width > 0.75',)
More information about explanations can be found in the Explainer Principles page, the Explaining Classification page and the Explaining Regression page.