Majoritary Reasons
Let $f$ be a Boolean function represented by a random forest $RF$, $x$ be an instance and $1$ (resp. $0$) the prediction of $RF$ on $x$ ($f(x) = 1$ (resp $f(x)=0$)). A majoritary reason for $x$ is a term $t$ covering $x$, such that $t$ is an implicant of at least a majoritary of decision trees $T_i$ that is minimal w.r.t. set inclusion.
In general, the notions of majoritary reason and of sufficient reason do not coincide. Indeed, a sufficient reason is a prime implicant (covering $x$) of the forest $F$, while a majoritary reason is an implicant $t$ (covering $x$) of a majority of decision trees in the forest $F$. More information about majoritary reasons can be found in the article Trading Complexity for Sparsity in Random Forest Explanations.
| <ExplainerRF Object>.majoritary_reason(*, n=1, n_iterations=50, time_limit=None, seed=0): |
|---|
If n is set to 1, this method calls a greedy algorithm to compute a majoritary reason. The algorithm is run n_iterations times and the smallest majoritary reason found is returned. On the contrary, if n is set to Explainer.ALL, a CNF formula associated to the random forest is created and a SAT solver is called to solve it. Each solution corresponds to a majoritary reason.Excluded features are supported. The reasons are in the form of binary variables, you must use the to_features method if you want a representation based on the features considered at start. |
time_limit Integer None: The time limit of the method in seconds. Set this to None to give this process an infinite amount of time. Default value is None. |
n Integer: The number of majoritary reasons computed. Currently n=1 or n=Explainer.ALL is only supported. Default value is 1. |
n_iterations Integer: Only used if n=1. It is the number of iterations done by the greedy algorithm. Default value is 50. |
seed Integer: The seed when the greedy algorithm is used. Set to 0 this parameter in order to use a random seed. Default value is 0 |
As for minimal sufficient reasons, a natural way of improving the quality of majoritary reasons is to seek for the most parsimonious ones. A minimal majoritary reason for $x$ is a majoritary reason for $x$ that contains a minimal number of literals. In other words, a minimal majoritary reason has a minimal size.
| <ExplainerRF Object>.minimal_majoritary_reason(*, n=1, time_limit=None): |
|---|
| This method considers a CNF formula representing the random forest as hard clauses and adds binary variables representing the instance as unary soft clauses with weights equal to 1. Several calls to a MAXSAT solver (OPENWBO) are performed and the result of each call is a minimal majoritary reason. The method prevents from finding the same reason twice or more by adding clauses (called blocking clauses) between each invocation. Returns n minimal majoritary reason of the current instance in a Tuple (when n is set to 1, does not return a Tuple but just the reason). Supports the excluded features. The reasons are in the form of binary variables, you must use the to_features method if you want to convert them into features. |
n Integer: The number of majoritary reasons computed. Currently n=1 or n=Exmplainer.ALL is only supported. Default value is 1. |
time_limit Integer None: The time limit of the method in seconds. Set this to None to give this process an infinite amount of time. Default value is None. |
One can also find preferred majoritary reasons. Indeed, the user may prefer reason containing some features and can provide weights in order to select some reasons instead of others. Please take a look to the Preferences page for more informations on preference handling.
| <ExplainerRF Object>.prefered_majoritary_reason(*, method, n=1, time_limit=None, weights=None, features_partition=None): |
|---|
This method considers a CNF formula representing the random forest as hard clauses and adds binary variables representing the instance as unary soft clauses with weights equal to different values depending the method used. If the method is PreferredReasonMethod.WEIGHTS then weights are given by the parameter weights, otherwise this parameter is useless. If the method is PreferredReasonMethod.INCLUSION_PREFERRED then the partition of features is given by the parameter features_partition, otherwise this parameter is useless. To derived a preferred reason, several calls to a MAXSAT solver (OPENWBO) are performed and the result of each call is a preferred majoritary reason. The method prevents from finding the same reason twice or more by adding clauses (called blocking clauses) between each invocation.Returns n preferred majoritary reason of the current instance in a Tuple (when n is set to 1, does not return a Tuple but just the reason). Supports the excluded features. The reasons are in the form of binary variables, you must use the to_features method if you want a representation based on the features considered at start. |
method PreferredReasonMethod.WEIGHTS PreferredReasonMethods.SHAPLEY PreferredReasonMethod.FEATURE_IMPORTANCE PreferredReasonMethod.WORD_FREQUENCY: The method used to derive preferred majoritary reasons. |
n Integer: The number of majoritary reasons computed. Currently n=1 or n=Exmplainer.ALL is only supported. Default value is 1. |
time_limit Integer None: The time limit of the method in seconds. Sets this to None to give this process an infinite amount of time. Default value is None. |
weights List: The weights (list of floats, one per feature, used to discriminate features. Only usefull when method is PreferredReasonMethod.WEIGHTS. Default value is None. |
features_partition List of List: The partition of features. The first elements are preferred to the second ones, and so on. Only usefull when method is PreferredReasonMethod.INCLUSION_PREFERRED. Default value is None. |
The PyXAI library also provides a way to test that a reason actually is a majority reason:
| <ExplainerRF Object>.is_majoritary_reason(reason): |
|---|
This method checks whether a reason is a majoritary reason. It first calls the method is_implicant to check if this reason leads to the correct prediction or not. Then it verifies the minimality of the reason in the sense of set inclusion. To do that, it deletes a literal of the reason, tests with is_implicant that this new implicant is not a majority reason and puts back this literal. The method repeats this operation on every literal of the reason. The method is deterministic and returns True or False. |
reason List of Integer: The reason to be checked. |
Example from Hand-Crafted Trees
For this example, we take the Random Forest of the Building Models page consisting of 4 binary features (𝑥1, 𝑥2, 𝑥3 and 𝑥4).
The following figure shows in red and bold a minimal majoritary reason $(x_2, x_3, x_4)$ for the instance $(1,1,1,1)$. 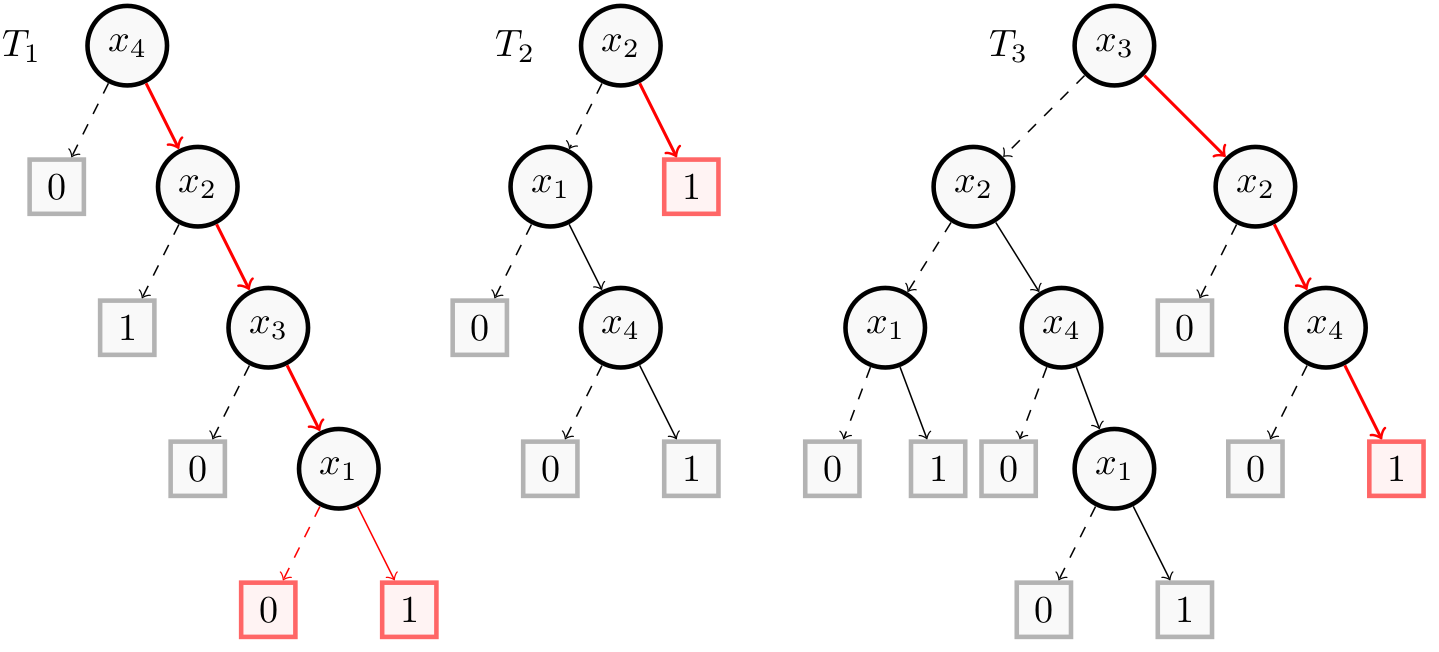
For the majoritary reason $(x_2, x_3, x_4)$, we can see that even if $T_1$ leads to a prediction equal to 0 (when we have $-x_1$), there is always a majority of Decision Trees (i.e. $T_2$ and $T_3$) that give a prediction of 1.
The next figure shows in blue and bold a minimal majoritary reason $(x_2, -x_4)$ for the instance $(0,1,0,0)$.
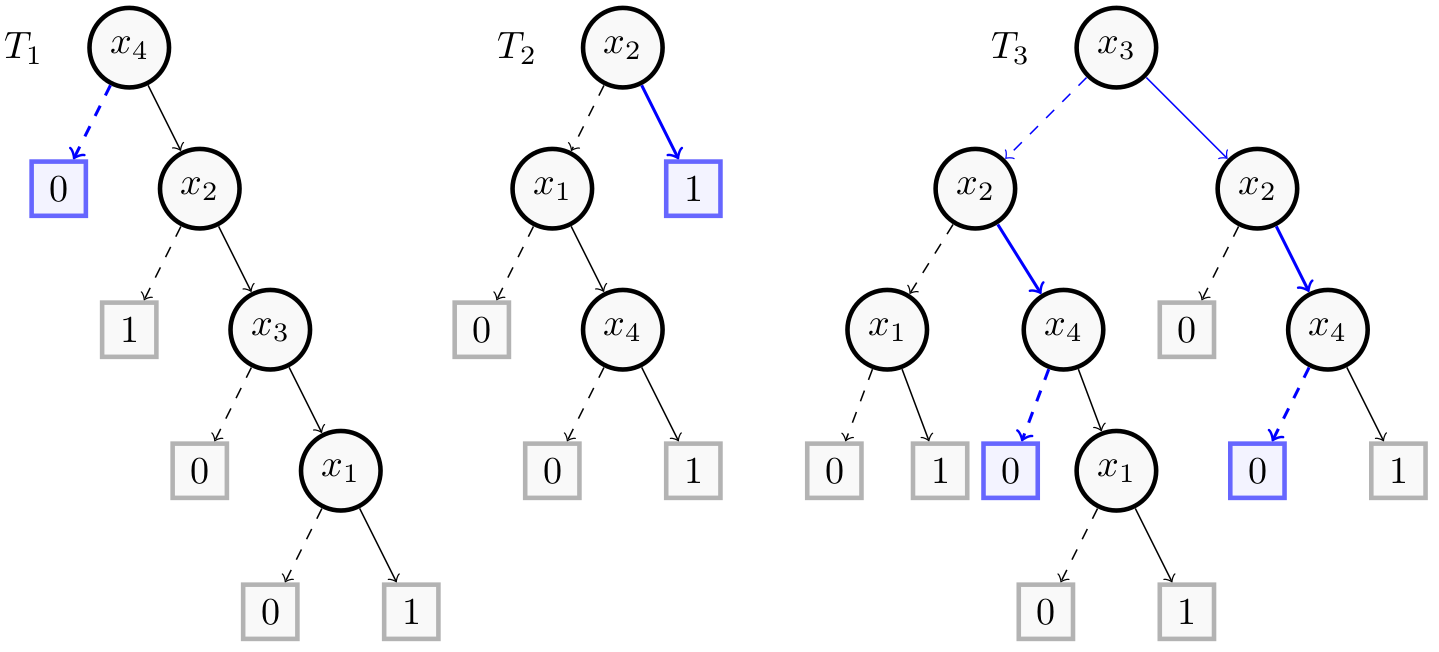
For $(x_2, -x_4)$, $T_2$ always gives a prediction of 1 while $T_1$ and $T_3$ always give a prediction of 0. So in all cases we have a majority of trees ($T_1$ and $T_3$) that lead to the right prediction (0).
Now, we show how to get them with PyXAI. We start by building the random forest:
from pyxai import Builder, Explainer
nodeT1_1 = Builder.DecisionNode(1, left=0, right=1)
nodeT1_3 = Builder.DecisionNode(3, left=0, right=nodeT1_1)
nodeT1_2 = Builder.DecisionNode(2, left=1, right=nodeT1_3)
nodeT1_4 = Builder.DecisionNode(4, left=0, right=nodeT1_2)
tree1 = Builder.DecisionTree(4, nodeT1_4, force_features_equal_to_binaries=True)
nodeT2_4 = Builder.DecisionNode(4, left=0, right=1)
nodeT2_1 = Builder.DecisionNode(1, left=0, right=nodeT2_4)
nodeT2_2 = Builder.DecisionNode(2, left=nodeT2_1, right=1)
tree2 = Builder.DecisionTree(4, nodeT2_2, force_features_equal_to_binaries=True) #4 features but only 3 used
nodeT3_1_1 = Builder.DecisionNode(1, left=0, right=1)
nodeT3_1_2 = Builder.DecisionNode(1, left=0, right=1)
nodeT3_4_1 = Builder.DecisionNode(4, left=0, right=nodeT3_1_1)
nodeT3_4_2 = Builder.DecisionNode(4, left=0, right=1)
nodeT3_2_1 = Builder.DecisionNode(2, left=nodeT3_1_2, right=nodeT3_4_1)
nodeT3_2_2 = Builder.DecisionNode(2, left=0, right=nodeT3_4_2)
nodeT3_3_1 = Builder.DecisionNode(3, left=nodeT3_2_1, right=nodeT3_2_2)
tree3 = Builder.DecisionTree(4, nodeT3_3_1, force_features_equal_to_binaries=True)
forest = Builder.RandomForest([tree1, tree2, tree3], n_classes=2)
We compute a majoritary reason for each of these two instances:
explainer = Explainer.initialize(forest)
explainer.set_instance((1,1,1,1))
majoritary = explainer.majoritary_reason(seed=1234)
print("target_prediction:", explainer.target_prediction)
print("majoritary:", majoritary)
assert explainer.is_majoritary_reason(majoritary)
minimal = explainer.minimal_majoritary_reason()
print("minimal:", minimal)
assert minimal == (2,3 , 4), "The minimal reason is not good !"
print("-------------------------------")
instance = (0,1,0,0)
explainer.set_instance(instance)
print("target_prediction:", explainer.target_prediction)
majoritary = explainer.majoritary_reason()
print("majoritary:", majoritary)
minimal = explainer.minimal_majoritary_reason()
print("minimal:", minimal)
assert minimal == (2, -4), "The minimal reason is not good !"
target_prediction: 1
majoritary: (1, 2, 4)
minimal: (2, 3, 4)
-------------------------------
target_prediction: 0
majoritary: (-1, -4)
minimal: (2, -4)
Example from a Real Dataset
For this example, we take the compas dataset. We create a model using the hold-out approach (by default, the test size is set to 30%) and select a well-classified instance.
from pyxai import Learning, Explainer
learner = Learning.Scikitlearn("../../../dataset/compas.csv", learner_type=Learning.CLASSIFICATION)
model = learner.evaluate(method=Learning.HOLD_OUT, output=Learning.RF)
instance, prediction = learner.get_instances(model, n=1, correct=True)
data:
Number_of_Priors score_factor Age_Above_FourtyFive
0 0 0 1 \
1 0 0 0
2 4 0 0
3 0 0 0
4 14 1 0
... ... ... ...
6167 0 1 0
6168 0 0 0
6169 0 0 1
6170 3 0 0
6171 2 0 0
Age_Below_TwentyFive African_American Asian Hispanic
0 0 0 0 0 \
1 0 1 0 0
2 1 1 0 0
3 0 0 0 0
4 0 0 0 0
... ... ... ... ...
6167 1 1 0 0
6168 1 1 0 0
6169 0 0 0 0
6170 0 1 0 0
6171 1 0 0 1
Native_American Other Female Misdemeanor Two_yr_Recidivism
0 0 1 0 0 0
1 0 0 0 0 1
2 0 0 0 0 1
3 0 1 0 1 0
4 0 0 0 0 1
... ... ... ... ... ...
6167 0 0 0 0 0
6168 0 0 0 0 0
6169 0 1 0 0 0
6170 0 0 1 1 0
6171 0 0 1 0 1
[6172 rows x 12 columns]
-------------- Information ---------------
Dataset name: ../../../dataset/compas.csv
nFeatures (nAttributes, with the labels): 12
nInstances (nObservations): 6172
nLabels: 2
--------------- Evaluation ---------------
method: HoldOut
output: RF
learner_type: Classification
learner_options: {'max_depth': None, 'random_state': 0}
--------- Evaluation Information ---------
For the evaluation number 0:
metrics:
accuracy: 65.71274298056156
nTraining instances: 4320
nTest instances: 1852
--------------- Explainer ----------------
For the evaluation number 0:
**Random Forest Model**
nClasses: 2
nTrees: 100
nVariables: 68
--------------- Instances ----------------
number of instances selected: 1
----------------------------------------------
We compute a majoritary reason for the instance and a minimal one.
explainer = Explainer.initialize(model, instance)
print("instance:", instance)
print("prediction:", prediction)
print()
majoritary_reason = explainer.majoritary_reason()
#for s in sufficient_reasons:
print("\nmajoritary reason:", majoritary_reason)
print("len majoritary reason:", len(majoritary_reason))
print("to features", explainer.to_features(majoritary_reason))
print("is majoritary reason: ", explainer.is_majoritary_reason(majoritary_reason))
print()
minimal = explainer.minimal_majoritary_reason()
print("\nminimal:", minimal)
print("minimal:", len(minimal))
print("to features", explainer.to_features(majoritary_reason))
print("is majoritary reason: ", explainer.is_majoritary_reason(majoritary_reason))
instance: [0 0 1 0 0 0 0 0 1 0 0]
prediction: 0
majoritary reason: (-1, -2, -3, -4, -6, -11, -14, -18)
len majoritary reason: 8
to features ('Number_of_Priors <= 0.5', 'score_factor <= 0.5', 'Age_Below_TwentyFive <= 0.5', 'African_American <= 0.5', 'Female <= 0.5')
is majoritary reason: True
minimal: (-1, -2, -3, -4, -6, -11, -13, -14)
minimal: 8
to features ('Number_of_Priors <= 0.5', 'score_factor <= 0.5', 'Age_Below_TwentyFive <= 0.5', 'African_American <= 0.5', 'Female <= 0.5')
is majoritary reason: True
Other types of explanations are presented in the Explanations Computation page.