Direct Reason
Let $BT$ be a boosted tree composed of {$T_1,\ldots T_n$} regression trees and $x$ an instance, the direct reason for $x$ is a subset of $t_{\vec x}$ (the binary form of the instance) corresponding to the conjunction for each $T_i$ of the term associated with the unique root-to-leaf path of $T_i$ that is compatible with $x$. Due to its simplicity, it is one of the easiest abductive explanation that can be computedn but it can be highly redundant. More information about the direct reason can be found in the article Computing Abductive Explanations for Boosted Regression Trees.
| <Explainer Object>.direct_reason(): |
|---|
Returns the direct reason for the current instance. Returns None if this reason contains some excluded features. All kinds of operators in the conditions are supported. This reason is in the form of binary variables, you must use the to_features method if you want to obtain a representation based on the features represented at start. |
The basic methods (initialize, set_instance, to_features, is_reason, …) of the explainer module used in the next examples are described in the Explainer Principles page.
Example from Hand-Crafted Trees
Let us consider a loan application scenario that will be used as a running example. The goal is to predict the amount of money that can be granted to an applicant described using three attributes ($A = {A_1, A_2, A_3}$).
- $A_1$ is a numerical attribute giving the income per month of the applicant
- $A_2$ is a categorical feature giving its employment status as ”employed”, ”unemployed” or ”self-employed”
- $A_3$ is a Boolean feature set to true if the customer is married, false otherwise.
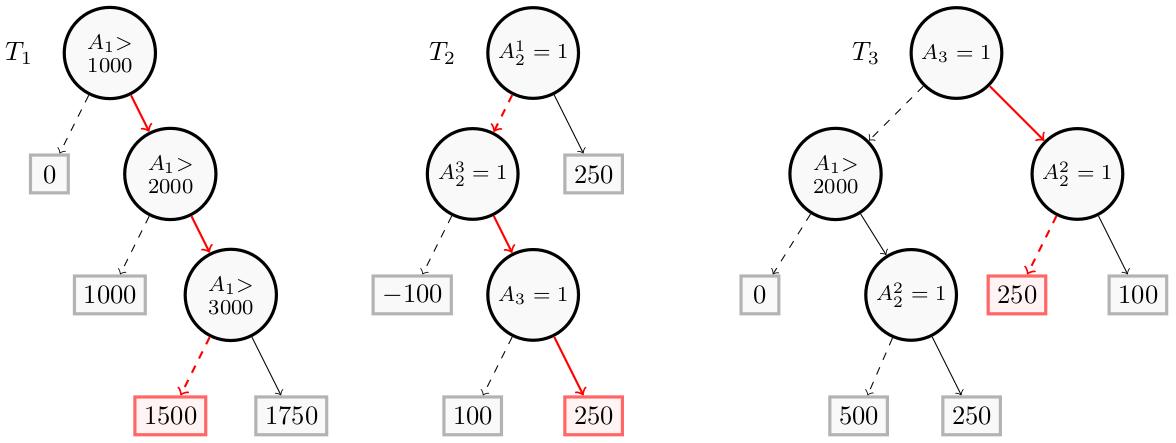
In this example:
- $A_1$ is represented by the feature identifier $F_1$
- $A_2$ has been one-hot encoded and is represented by feature identifiers $F_2$, $F_3$ and $F_4$, each of these features represents respectively the condition $A_2^{1} = employed$, $A_2^{2} = unemployed$ and $A_2^{3} = self-employed$
- $A_3$ is represented by the feature identifier $F_5$ and the condition $(A_3 = 1)$ (”the applicant is married”)
We consider the instance $x=(2200, 0, 0, 1, 1)$, corresponding to a person with a salary equal to 2200 per month, self employed (one hot encoded) and married. Then, $F(x) = 1500 + 250 + 250 = 2000$.
The direct reason for the instance $x = (2200, 0, 0, 1, 1)$ is in red and can be represented by ${A_1{>}2000, \overline{A_1{>}3000}, A_2^3, A_3}$.
We now show how to get it using PyXAI:
from pyxai import Builder, Explainer
node1_1 = Builder.DecisionNode(1, operator=Builder.GT, threshold=3000, left=1500, right=1750)
node1_2 = Builder.DecisionNode(1, operator=Builder.GT, threshold=2000, left=1000, right=node1_1)
node1_3 = Builder.DecisionNode(1, operator=Builder.GT, threshold=1000, left=0, right=node1_2)
tree1 = Builder.DecisionTree(5, node1_3)
node2_1 = Builder.DecisionNode(5, operator=Builder.EQ, threshold=1, left=100, right=250)
node2_2 = Builder.DecisionNode(4, operator=Builder.EQ, threshold=1, left=-100, right=node2_1)
node2_3 = Builder.DecisionNode(2, operator=Builder.EQ, threshold=1, left=node2_2, right=250)
tree2 = Builder.DecisionTree(5, node2_3)
node3_1 = Builder.DecisionNode(3, operator=Builder.EQ, threshold=1, left=500, right=250)
node3_2 = Builder.DecisionNode(3, operator=Builder.EQ, threshold=1, left=250, right=100)
node3_3 = Builder.DecisionNode(1, operator=Builder.GE, threshold=2000, left=0, right=node3_1)
node3_4 = Builder.DecisionNode(4, operator=Builder.EQ, threshold=1, left=node3_3, right=node3_2)
tree3 = Builder.DecisionTree(5, node3_4)
BT = Builder.BoostedTreesRegression([tree1, tree2, tree3])
We now compute the direct reason for this instance:
explainer = Explainer.initialize(BT)
explainer.set_instance((2200, 0, 0, 1, 1))
direct = explainer.direct_reason()
print("instance: (4,3,2,1)")
print("binary_representation:", explainer.binary_representation)
print("target_prediction:", explainer.target_prediction)
print("direct:", direct)
print("to_features:", explainer.to_features(direct))
instance: (4,3,2,1)
binary_representation: (1, 2, -3, -4, 5, 6, 7, -8)
target_prediction: 2000
direct: (1, 2, -3, -4, 5, 6, -8)
to_features: ('f1 in ]2000, 3000]', 'f2 != 1', 'f3 != 1', 'f4 == 1', 'f5 == 1')
As you can see, in this case, the direct reason corresponds to the full instance.
Example from a Real Dataset
For this example, we take the Houses-prices dataset (this one here). We create a model using the hold-out approach (by default, the test size is set to 30%) and select a well-classified instance. As this dataset contains strings, we encode the data using PyXAI’s Preprocessor:
from pyxai import Learning
preprocessor = Learning.Preprocessor("../../dataset/houses-prices.csv", target_feature="SalePrice", learner_type=Learning.REGRESSION)
preprocessor.unset_features(["Id"])
preprocessor.set_categorical_features(columns=[
"MSSubClass",
"Street",
"LotShape",
"LandContour",
"LotConfig",
"LandSlope",
"Neighborhood",
"Condition1",
"Condition2",
"BldgType",
"HouseStyle",
"OverallQual",
"OverallCond",
"RoofStyle",
"RoofMatl",
"ExterQual",
"ExterCond",
"Foundation",
"Heating",
"HeatingQC",
"CentralAir",
"PavedDrive",
"SaleCondition"])
preprocessor.set_numerical_features({
"LotArea": None,
"YearBuilt": None,
"YearRemodAdd": None,
"1stFlrSF": None,
"2ndFlrSF": None,
"LowQualFinSF": None,
"GrLivArea": None,
"FullBath": None,
"HalfBath": None,
"BedroomAbvGr": None,
"KitchenAbvGr": None,
"TotRmsAbvGrd": None,
"Fireplaces": None,
"WoodDeckSF": None,
"OpenPorchSF": None,
"EnclosedPorch": None,
"3SsnPorch": None,
"ScreenPorch": None,
"PoolArea": None,
"MiscVal": None,
"MoSold": None,
"YrSold": None
})
preprocessor.process()
dataset_name = "../../dataset/houses-prices.csv".split("/")[-1].split(".")[0]+"-converted"
preprocessor.export(dataset_name, output_directory="../../dataset")
Index(['Id', 'MSSubClass', 'LotArea', 'Street', 'LotShape', 'LandContour',
'LotConfig', 'LandSlope', 'Neighborhood', 'Condition1', 'Condition2',
'BldgType', 'HouseStyle', 'OverallQual', 'OverallCond', 'YearBuilt',
'YearRemodAdd', 'RoofStyle', 'RoofMatl', 'ExterQual', 'ExterCond',
'Foundation', 'Heating', 'HeatingQC', 'CentralAir', '1stFlrSF',
'2ndFlrSF', 'LowQualFinSF', 'GrLivArea', 'FullBath', 'HalfBath',
'BedroomAbvGr', 'KitchenAbvGr', 'TotRmsAbvGrd', 'Fireplaces',
'PavedDrive', 'WoodDeckSF', 'OpenPorchSF', 'EnclosedPorch', '3SsnPorch',
'ScreenPorch', 'PoolArea', 'MiscVal', 'MoSold', 'YrSold',
'SaleCondition', 'SalePrice'],
dtype='object')
--------------- Converter ---------------
Feature deleted: Id
One hot encoding new features for MSSubClass: 16
-> The feature Street is boolean! No One Hot Encoding for this features.
-> However, the boolean feature Street contains strings. A ordinal encoding must be performed.
One hot encoding new features for LotShape: 4
One hot encoding new features for LandContour: 4
One hot encoding new features for LotConfig: 5
One hot encoding new features for LandSlope: 3
One hot encoding new features for Neighborhood: 25
One hot encoding new features for Condition1: 9
One hot encoding new features for Condition2: 8
One hot encoding new features for BldgType: 5
One hot encoding new features for HouseStyle: 8
One hot encoding new features for OverallQual: 10
One hot encoding new features for OverallCond: 9
One hot encoding new features for RoofStyle: 6
One hot encoding new features for RoofMatl: 8
One hot encoding new features for ExterQual: 4
One hot encoding new features for ExterCond: 5
One hot encoding new features for Foundation: 6
One hot encoding new features for Heating: 6
One hot encoding new features for HeatingQC: 5
-> The feature CentralAir is boolean! No One Hot Encoding for this features.
-> However, the boolean feature CentralAir contains strings. A ordinal encoding must be performed.
One hot encoding new features for PavedDrive: 3
One hot encoding new features for SaleCondition: 6
Dataset saved: ../../dataset/houses-prices-converted.csv
Types saved: ../../dataset/houses-prices-converted.types
-----------------------------------------------
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
DataFrame.fillna with 'method' is deprecated and will raise in a future version. Use obj.ffill() or obj.bfill() instead.
Index(['Id', 'MSSubClass', 'LotArea', 'Street', 'LotShape', 'LandContour',
'LotConfig', 'LandSlope', 'Neighborhood', 'Condition1', 'Condition2',
'BldgType', 'HouseStyle', 'OverallQual', 'OverallCond', 'YearBuilt',
'YearRemodAdd', 'RoofStyle', 'RoofMatl', 'ExterQual', 'ExterCond',
'Foundation', 'Heating', 'HeatingQC', 'CentralAir', '1stFlrSF',
'2ndFlrSF', 'LowQualFinSF', 'GrLivArea', 'FullBath', 'HalfBath',
'BedroomAbvGr', 'KitchenAbvGr', 'TotRmsAbvGrd', 'Fireplaces',
'PavedDrive', 'WoodDeckSF', 'OpenPorchSF', 'EnclosedPorch', '3SsnPorch',
'ScreenPorch', 'PoolArea', 'MiscVal', 'MoSold', 'YrSold',
'SaleCondition', 'SalePrice'],
dtype='object')
--------------- Converter ---------------
Feature deleted: Id
One hot encoding new features for MSSubClass: 16
-> The feature Street is boolean! No One Hot Encoding for this features.
-> However, the boolean feature Street contains strings. A ordinal encoding must be performed.
One hot encoding new features for LotShape: 4
One hot encoding new features for LandContour: 4
One hot encoding new features for LotConfig: 5
One hot encoding new features for LandSlope: 3
One hot encoding new features for Neighborhood: 25
One hot encoding new features for Condition1: 9
One hot encoding new features for Condition2: 8
One hot encoding new features for BldgType: 5
One hot encoding new features for HouseStyle: 8
One hot encoding new features for OverallQual: 10
One hot encoding new features for OverallCond: 9
One hot encoding new features for RoofStyle: 6
One hot encoding new features for RoofMatl: 8
One hot encoding new features for ExterQual: 4
One hot encoding new features for ExterCond: 5
One hot encoding new features for Foundation: 6
One hot encoding new features for Heating: 6
One hot encoding new features for HeatingQC: 5
-> The feature CentralAir is boolean! No One Hot Encoding for this features.
-> However, the boolean feature CentralAir contains strings. A ordinal encoding must be performed.
One hot encoding new features for PavedDrive: 3
One hot encoding new features for SaleCondition: 6
Dataset saved: ../../dataset/houses-prices-converted_0.csv
Types saved: ../../dataset/houses-prices-converted_0.types
-----------------------------------------------
Now we produce a model and pick up an instance:
from pyxai import Learning, Explainer
learner = Learning.Xgboost("../../dataset/houses-prices-converted_0.csv", learner_type=Learning.REGRESSION)
model = learner.evaluate(method=Learning.HOLD_OUT, output=Learning.BT)
instance, prediction = learner.get_instances(model, n=1)
data:
MSSubClass_20 MSSubClass_30 MSSubClass_40 MSSubClass_45 \
0 0 0 0 0
1 1 0 0 0
2 0 0 0 0
3 0 0 0 0
4 0 0 0 0
... ... ... ... ...
2914 0 0 0 0
2915 0 0 0 0
2916 1 0 0 0
2917 0 0 0 0
2918 0 0 0 0
MSSubClass_50 MSSubClass_60 MSSubClass_70 MSSubClass_75 \
0 0 1 0 0
1 0 0 0 0
2 0 1 0 0
3 0 0 1 0
4 0 1 0 0
... ... ... ... ...
2914 0 0 0 0
2915 0 0 0 0
2916 0 0 0 0
2917 0 0 0 0
2918 0 1 0 0
MSSubClass_80 MSSubClass_85 ... MiscVal MoSold YrSold \
0 0 0 ... 0 2 2008
1 0 0 ... 0 5 2007
2 0 0 ... 0 9 2008
3 0 0 ... 0 2 2006
4 0 0 ... 0 12 2008
... ... ... ... ... ... ...
2914 0 0 ... 0 6 2006
2915 0 0 ... 0 4 2006
2916 0 0 ... 0 9 2006
2917 0 1 ... 700 7 2006
2918 0 0 ... 0 11 2006
SaleCondition_Abnorml SaleCondition_AdjLand SaleCondition_Alloca \
0 0 0 0
1 0 0 0
2 0 0 0
3 1 0 0
4 0 0 0
... ... ... ...
2914 0 0 0
2915 1 0 0
2916 1 0 0
2917 0 0 0
2918 0 0 0
SaleCondition_Family SaleCondition_Normal SaleCondition_Partial \
0 0 1 0
1 0 1 0
2 0 1 0
3 0 0 0
4 0 1 0
... ... ... ...
2914 0 1 0
2915 0 0 0
2916 0 0 0
2917 0 1 0
2918 0 1 0
SalePrice
0 208500.000000
1 181500.000000
2 223500.000000
3 140000.000000
4 250000.000000
... ...
2914 167081.220949
2915 164788.778231
2916 219222.423400
2917 184924.279659
2918 187741.866657
[2919 rows x 180 columns]
-------------- Information ---------------
Dataset name: ../../dataset/houses-prices-converted_0.csv
nFeatures (nAttributes, with the labels): 180
nInstances (nObservations): 2919
nLabels: None
--------------- Evaluation ---------------
method: HoldOut
output: BT
learner_type: Regression
learner_options: {'seed': 0, 'max_depth': None}
--------- Evaluation Information ---------
For the evaluation number 0:
metrics:
mean_squared_error: 1997310553.8387074
root_mean_squared_error: 44691.28051240765
mean_absolute_error: 29588.51328599622
nTraining instances: 2043
nTest instances: 876
--------------- Explainer ----------------
For the evaluation number 0:
**Boosted Tree model**
NClasses: None
nTrees: 100
nVariables: 1696
--------------- Instances ----------------
number of instances selected: 1
----------------------------------------------
Finally, we display the direct reason for this instance. Note that the theory created by the PyXAI’s Preprocessor is achieved by adding the parameter features_type="../../dataset/houses-prices-converted_0.types" to the initialize method. More information about theories is available on this page.
explainer = Explainer.initialize(model, instance, features_type="../../dataset/houses-prices-converted_0.types")
print("instance:", instance)
print("prediction:", prediction)
print()
direct_reason = explainer.direct_reason()
print("len binary representation:", len(explainer.binary_representation))
print("len direct:", len(direct_reason))
print("is_reason:", explainer.is_reason(direct_reason))
print("to_features:", explainer.to_features(direct_reason))
--------- Theory Feature Types -----------
Before the encoding (without one hot encoded features), we have:
Numerical features: 22
Categorical features: 21
Binary features: 2
Number of features: 45
Values of categorical features: {'MSSubClass_20': ['MSSubClass', 20, [20, 30, 40, 45, 50, 60, 70, 75, 80, 85, 90, 120, 150, 160, 180, 190]], 'MSSubClass_30': ['MSSubClass', 30, [20, 30, 40, 45, 50, 60, 70, 75, 80, 85, 90, 120, 150, 160, 180, 190]], 'MSSubClass_40': ['MSSubClass', 40, [20, 30, 40, 45, 50, 60, 70, 75, 80, 85, 90, 120, 150, 160, 180, 190]], 'MSSubClass_45': ['MSSubClass', 45, [20, 30, 40, 45, 50, 60, 70, 75, 80, 85, 90, 120, 150, 160, 180, 190]], 'MSSubClass_50': ['MSSubClass', 50, [20, 30, 40, 45, 50, 60, 70, 75, 80, 85, 90, 120, 150, 160, 180, 190]], 'MSSubClass_60': ['MSSubClass', 60, [20, 30, 40, 45, 50, 60, 70, 75, 80, 85, 90, 120, 150, 160, 180, 190]], 'MSSubClass_70': ['MSSubClass', 70, [20, 30, 40, 45, 50, 60, 70, 75, 80, 85, 90, 120, 150, 160, 180, 190]], 'MSSubClass_75': ['MSSubClass', 75, [20, 30, 40, 45, 50, 60, 70, 75, 80, 85, 90, 120, 150, 160, 180, 190]], 'MSSubClass_80': ['MSSubClass', 80, [20, 30, 40, 45, 50, 60, 70, 75, 80, 85, 90, 120, 150, 160, 180, 190]], 'MSSubClass_85': ['MSSubClass', 85, [20, 30, 40, 45, 50, 60, 70, 75, 80, 85, 90, 120, 150, 160, 180, 190]], 'MSSubClass_90': ['MSSubClass', 90, [20, 30, 40, 45, 50, 60, 70, 75, 80, 85, 90, 120, 150, 160, 180, 190]], 'MSSubClass_120': ['MSSubClass', 120, [20, 30, 40, 45, 50, 60, 70, 75, 80, 85, 90, 120, 150, 160, 180, 190]], 'MSSubClass_150': ['MSSubClass', 150, [20, 30, 40, 45, 50, 60, 70, 75, 80, 85, 90, 120, 150, 160, 180, 190]], 'MSSubClass_160': ['MSSubClass', 160, [20, 30, 40, 45, 50, 60, 70, 75, 80, 85, 90, 120, 150, 160, 180, 190]], 'MSSubClass_180': ['MSSubClass', 180, [20, 30, 40, 45, 50, 60, 70, 75, 80, 85, 90, 120, 150, 160, 180, 190]], 'MSSubClass_190': ['MSSubClass', 190, [20, 30, 40, 45, 50, 60, 70, 75, 80, 85, 90, 120, 150, 160, 180, 190]], 'LotShape_IR1': ['LotShape', 'IR1', ['IR1', 'IR2', 'IR3', 'Reg']], 'LotShape_IR2': ['LotShape', 'IR2', ['IR1', 'IR2', 'IR3', 'Reg']], 'LotShape_IR3': ['LotShape', 'IR3', ['IR1', 'IR2', 'IR3', 'Reg']], 'LotShape_Reg': ['LotShape', 'Reg', ['IR1', 'IR2', 'IR3', 'Reg']], 'LandContour_Bnk': ['LandContour', 'Bnk', ['Bnk', 'HLS', 'Low', 'Lvl']], 'LandContour_HLS': ['LandContour', 'HLS', ['Bnk', 'HLS', 'Low', 'Lvl']], 'LandContour_Low': ['LandContour', 'Low', ['Bnk', 'HLS', 'Low', 'Lvl']], 'LandContour_Lvl': ['LandContour', 'Lvl', ['Bnk', 'HLS', 'Low', 'Lvl']], 'LotConfig_Corner': ['LotConfig', 'Corner', ['Corner', 'CulDSac', 'FR2', 'FR3', 'Inside']], 'LotConfig_CulDSac': ['LotConfig', 'CulDSac', ['Corner', 'CulDSac', 'FR2', 'FR3', 'Inside']], 'LotConfig_FR2': ['LotConfig', 'FR2', ['Corner', 'CulDSac', 'FR2', 'FR3', 'Inside']], 'LotConfig_FR3': ['LotConfig', 'FR3', ['Corner', 'CulDSac', 'FR2', 'FR3', 'Inside']], 'LotConfig_Inside': ['LotConfig', 'Inside', ['Corner', 'CulDSac', 'FR2', 'FR3', 'Inside']], 'LandSlope_Gtl': ['LandSlope', 'Gtl', ['Gtl', 'Mod', 'Sev']], 'LandSlope_Mod': ['LandSlope', 'Mod', ['Gtl', 'Mod', 'Sev']], 'LandSlope_Sev': ['LandSlope', 'Sev', ['Gtl', 'Mod', 'Sev']], 'Neighborhood_Blmngtn': ['Neighborhood', 'Blmngtn', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_Blueste': ['Neighborhood', 'Blueste', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_BrDale': ['Neighborhood', 'BrDale', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_BrkSide': ['Neighborhood', 'BrkSide', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_ClearCr': ['Neighborhood', 'ClearCr', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_CollgCr': ['Neighborhood', 'CollgCr', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_Crawfor': ['Neighborhood', 'Crawfor', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_Edwards': ['Neighborhood', 'Edwards', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_Gilbert': ['Neighborhood', 'Gilbert', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_IDOTRR': ['Neighborhood', 'IDOTRR', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_MeadowV': ['Neighborhood', 'MeadowV', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_Mitchel': ['Neighborhood', 'Mitchel', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_NAmes': ['Neighborhood', 'NAmes', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_NPkVill': ['Neighborhood', 'NPkVill', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_NWAmes': ['Neighborhood', 'NWAmes', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_NoRidge': ['Neighborhood', 'NoRidge', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_NridgHt': ['Neighborhood', 'NridgHt', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_OldTown': ['Neighborhood', 'OldTown', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_SWISU': ['Neighborhood', 'SWISU', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_Sawyer': ['Neighborhood', 'Sawyer', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_SawyerW': ['Neighborhood', 'SawyerW', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_Somerst': ['Neighborhood', 'Somerst', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_StoneBr': ['Neighborhood', 'StoneBr', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_Timber': ['Neighborhood', 'Timber', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Neighborhood_Veenker': ['Neighborhood', 'Veenker', ['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr', 'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel', 'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown', 'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber', 'Veenker']], 'Condition1_Artery': ['Condition1', 'Artery', ['Artery', 'Feedr', 'Norm', 'PosA', 'PosN', 'RRAe', 'RRAn', 'RRNe', 'RRNn']], 'Condition1_Feedr': ['Condition1', 'Feedr', ['Artery', 'Feedr', 'Norm', 'PosA', 'PosN', 'RRAe', 'RRAn', 'RRNe', 'RRNn']], 'Condition1_Norm': ['Condition1', 'Norm', ['Artery', 'Feedr', 'Norm', 'PosA', 'PosN', 'RRAe', 'RRAn', 'RRNe', 'RRNn']], 'Condition1_PosA': ['Condition1', 'PosA', ['Artery', 'Feedr', 'Norm', 'PosA', 'PosN', 'RRAe', 'RRAn', 'RRNe', 'RRNn']], 'Condition1_PosN': ['Condition1', 'PosN', ['Artery', 'Feedr', 'Norm', 'PosA', 'PosN', 'RRAe', 'RRAn', 'RRNe', 'RRNn']], 'Condition1_RRAe': ['Condition1', 'RRAe', ['Artery', 'Feedr', 'Norm', 'PosA', 'PosN', 'RRAe', 'RRAn', 'RRNe', 'RRNn']], 'Condition1_RRAn': ['Condition1', 'RRAn', ['Artery', 'Feedr', 'Norm', 'PosA', 'PosN', 'RRAe', 'RRAn', 'RRNe', 'RRNn']], 'Condition1_RRNe': ['Condition1', 'RRNe', ['Artery', 'Feedr', 'Norm', 'PosA', 'PosN', 'RRAe', 'RRAn', 'RRNe', 'RRNn']], 'Condition1_RRNn': ['Condition1', 'RRNn', ['Artery', 'Feedr', 'Norm', 'PosA', 'PosN', 'RRAe', 'RRAn', 'RRNe', 'RRNn']], 'Condition2_Artery': ['Condition2', 'Artery', ['Artery', 'Feedr', 'Norm', 'PosA', 'PosN', 'RRAe', 'RRAn', 'RRNn']], 'Condition2_Feedr': ['Condition2', 'Feedr', ['Artery', 'Feedr', 'Norm', 'PosA', 'PosN', 'RRAe', 'RRAn', 'RRNn']], 'Condition2_Norm': ['Condition2', 'Norm', ['Artery', 'Feedr', 'Norm', 'PosA', 'PosN', 'RRAe', 'RRAn', 'RRNn']], 'Condition2_PosA': ['Condition2', 'PosA', ['Artery', 'Feedr', 'Norm', 'PosA', 'PosN', 'RRAe', 'RRAn', 'RRNn']], 'Condition2_PosN': ['Condition2', 'PosN', ['Artery', 'Feedr', 'Norm', 'PosA', 'PosN', 'RRAe', 'RRAn', 'RRNn']], 'Condition2_RRAe': ['Condition2', 'RRAe', ['Artery', 'Feedr', 'Norm', 'PosA', 'PosN', 'RRAe', 'RRAn', 'RRNn']], 'Condition2_RRAn': ['Condition2', 'RRAn', ['Artery', 'Feedr', 'Norm', 'PosA', 'PosN', 'RRAe', 'RRAn', 'RRNn']], 'Condition2_RRNn': ['Condition2', 'RRNn', ['Artery', 'Feedr', 'Norm', 'PosA', 'PosN', 'RRAe', 'RRAn', 'RRNn']], 'BldgType_1Fam': ['BldgType', '1Fam', ['1Fam', '2fmCon', 'Duplex', 'Twnhs', 'TwnhsE']], 'BldgType_2fmCon': ['BldgType', '2fmCon', ['1Fam', '2fmCon', 'Duplex', 'Twnhs', 'TwnhsE']], 'BldgType_Duplex': ['BldgType', 'Duplex', ['1Fam', '2fmCon', 'Duplex', 'Twnhs', 'TwnhsE']], 'BldgType_Twnhs': ['BldgType', 'Twnhs', ['1Fam', '2fmCon', 'Duplex', 'Twnhs', 'TwnhsE']], 'BldgType_TwnhsE': ['BldgType', 'TwnhsE', ['1Fam', '2fmCon', 'Duplex', 'Twnhs', 'TwnhsE']], 'HouseStyle_1.5Fin': ['HouseStyle', '1.5Fin', ['1.5Fin', '1.5Unf', '1Story', '2.5Fin', '2.5Unf', '2Story', 'SFoyer', 'SLvl']], 'HouseStyle_1.5Unf': ['HouseStyle', '1.5Unf', ['1.5Fin', '1.5Unf', '1Story', '2.5Fin', '2.5Unf', '2Story', 'SFoyer', 'SLvl']], 'HouseStyle_1Story': ['HouseStyle', '1Story', ['1.5Fin', '1.5Unf', '1Story', '2.5Fin', '2.5Unf', '2Story', 'SFoyer', 'SLvl']], 'HouseStyle_2.5Fin': ['HouseStyle', '2.5Fin', ['1.5Fin', '1.5Unf', '1Story', '2.5Fin', '2.5Unf', '2Story', 'SFoyer', 'SLvl']], 'HouseStyle_2.5Unf': ['HouseStyle', '2.5Unf', ['1.5Fin', '1.5Unf', '1Story', '2.5Fin', '2.5Unf', '2Story', 'SFoyer', 'SLvl']], 'HouseStyle_2Story': ['HouseStyle', '2Story', ['1.5Fin', '1.5Unf', '1Story', '2.5Fin', '2.5Unf', '2Story', 'SFoyer', 'SLvl']], 'HouseStyle_SFoyer': ['HouseStyle', 'SFoyer', ['1.5Fin', '1.5Unf', '1Story', '2.5Fin', '2.5Unf', '2Story', 'SFoyer', 'SLvl']], 'HouseStyle_SLvl': ['HouseStyle', 'SLvl', ['1.5Fin', '1.5Unf', '1Story', '2.5Fin', '2.5Unf', '2Story', 'SFoyer', 'SLvl']], 'OverallQual_1': ['OverallQual', 1, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]], 'OverallQual_2': ['OverallQual', 2, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]], 'OverallQual_3': ['OverallQual', 3, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]], 'OverallQual_4': ['OverallQual', 4, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]], 'OverallQual_5': ['OverallQual', 5, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]], 'OverallQual_6': ['OverallQual', 6, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]], 'OverallQual_7': ['OverallQual', 7, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]], 'OverallQual_8': ['OverallQual', 8, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]], 'OverallQual_9': ['OverallQual', 9, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]], 'OverallQual_10': ['OverallQual', 10, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]], 'OverallCond_1': ['OverallCond', 1, [1, 2, 3, 4, 5, 6, 7, 8, 9]], 'OverallCond_2': ['OverallCond', 2, [1, 2, 3, 4, 5, 6, 7, 8, 9]], 'OverallCond_3': ['OverallCond', 3, [1, 2, 3, 4, 5, 6, 7, 8, 9]], 'OverallCond_4': ['OverallCond', 4, [1, 2, 3, 4, 5, 6, 7, 8, 9]], 'OverallCond_5': ['OverallCond', 5, [1, 2, 3, 4, 5, 6, 7, 8, 9]], 'OverallCond_6': ['OverallCond', 6, [1, 2, 3, 4, 5, 6, 7, 8, 9]], 'OverallCond_7': ['OverallCond', 7, [1, 2, 3, 4, 5, 6, 7, 8, 9]], 'OverallCond_8': ['OverallCond', 8, [1, 2, 3, 4, 5, 6, 7, 8, 9]], 'OverallCond_9': ['OverallCond', 9, [1, 2, 3, 4, 5, 6, 7, 8, 9]], 'RoofStyle_Flat': ['RoofStyle', 'Flat', ['Flat', 'Gable', 'Gambrel', 'Hip', 'Mansard', 'Shed']], 'RoofStyle_Gable': ['RoofStyle', 'Gable', ['Flat', 'Gable', 'Gambrel', 'Hip', 'Mansard', 'Shed']], 'RoofStyle_Gambrel': ['RoofStyle', 'Gambrel', ['Flat', 'Gable', 'Gambrel', 'Hip', 'Mansard', 'Shed']], 'RoofStyle_Hip': ['RoofStyle', 'Hip', ['Flat', 'Gable', 'Gambrel', 'Hip', 'Mansard', 'Shed']], 'RoofStyle_Mansard': ['RoofStyle', 'Mansard', ['Flat', 'Gable', 'Gambrel', 'Hip', 'Mansard', 'Shed']], 'RoofStyle_Shed': ['RoofStyle', 'Shed', ['Flat', 'Gable', 'Gambrel', 'Hip', 'Mansard', 'Shed']], 'RoofMatl_ClyTile': ['RoofMatl', 'ClyTile', ['ClyTile', 'CompShg', 'Membran', 'Metal', 'Roll', 'Tar&Grv', 'WdShake', 'WdShngl']], 'RoofMatl_CompShg': ['RoofMatl', 'CompShg', ['ClyTile', 'CompShg', 'Membran', 'Metal', 'Roll', 'Tar&Grv', 'WdShake', 'WdShngl']], 'RoofMatl_Membran': ['RoofMatl', 'Membran', ['ClyTile', 'CompShg', 'Membran', 'Metal', 'Roll', 'Tar&Grv', 'WdShake', 'WdShngl']], 'RoofMatl_Metal': ['RoofMatl', 'Metal', ['ClyTile', 'CompShg', 'Membran', 'Metal', 'Roll', 'Tar&Grv', 'WdShake', 'WdShngl']], 'RoofMatl_Roll': ['RoofMatl', 'Roll', ['ClyTile', 'CompShg', 'Membran', 'Metal', 'Roll', 'Tar&Grv', 'WdShake', 'WdShngl']], 'RoofMatl_Tar&Grv': ['RoofMatl', 'Tar&Grv', ['ClyTile', 'CompShg', 'Membran', 'Metal', 'Roll', 'Tar&Grv', 'WdShake', 'WdShngl']], 'RoofMatl_WdShake': ['RoofMatl', 'WdShake', ['ClyTile', 'CompShg', 'Membran', 'Metal', 'Roll', 'Tar&Grv', 'WdShake', 'WdShngl']], 'RoofMatl_WdShngl': ['RoofMatl', 'WdShngl', ['ClyTile', 'CompShg', 'Membran', 'Metal', 'Roll', 'Tar&Grv', 'WdShake', 'WdShngl']], 'ExterQual_Ex': ['ExterQual', 'Ex', ['Ex', 'Fa', 'Gd', 'TA']], 'ExterQual_Fa': ['ExterQual', 'Fa', ['Ex', 'Fa', 'Gd', 'TA']], 'ExterQual_Gd': ['ExterQual', 'Gd', ['Ex', 'Fa', 'Gd', 'TA']], 'ExterQual_TA': ['ExterQual', 'TA', ['Ex', 'Fa', 'Gd', 'TA']], 'ExterCond_Ex': ['ExterCond', 'Ex', ['Ex', 'Fa', 'Gd', 'Po', 'TA']], 'ExterCond_Fa': ['ExterCond', 'Fa', ['Ex', 'Fa', 'Gd', 'Po', 'TA']], 'ExterCond_Gd': ['ExterCond', 'Gd', ['Ex', 'Fa', 'Gd', 'Po', 'TA']], 'ExterCond_Po': ['ExterCond', 'Po', ['Ex', 'Fa', 'Gd', 'Po', 'TA']], 'ExterCond_TA': ['ExterCond', 'TA', ['Ex', 'Fa', 'Gd', 'Po', 'TA']], 'Foundation_BrkTil': ['Foundation', 'BrkTil', ['BrkTil', 'CBlock', 'PConc', 'Slab', 'Stone', 'Wood']], 'Foundation_CBlock': ['Foundation', 'CBlock', ['BrkTil', 'CBlock', 'PConc', 'Slab', 'Stone', 'Wood']], 'Foundation_PConc': ['Foundation', 'PConc', ['BrkTil', 'CBlock', 'PConc', 'Slab', 'Stone', 'Wood']], 'Foundation_Slab': ['Foundation', 'Slab', ['BrkTil', 'CBlock', 'PConc', 'Slab', 'Stone', 'Wood']], 'Foundation_Stone': ['Foundation', 'Stone', ['BrkTil', 'CBlock', 'PConc', 'Slab', 'Stone', 'Wood']], 'Foundation_Wood': ['Foundation', 'Wood', ['BrkTil', 'CBlock', 'PConc', 'Slab', 'Stone', 'Wood']], 'Heating_Floor': ['Heating', 'Floor', ['Floor', 'GasA', 'GasW', 'Grav', 'OthW', 'Wall']], 'Heating_GasA': ['Heating', 'GasA', ['Floor', 'GasA', 'GasW', 'Grav', 'OthW', 'Wall']], 'Heating_GasW': ['Heating', 'GasW', ['Floor', 'GasA', 'GasW', 'Grav', 'OthW', 'Wall']], 'Heating_Grav': ['Heating', 'Grav', ['Floor', 'GasA', 'GasW', 'Grav', 'OthW', 'Wall']], 'Heating_OthW': ['Heating', 'OthW', ['Floor', 'GasA', 'GasW', 'Grav', 'OthW', 'Wall']], 'Heating_Wall': ['Heating', 'Wall', ['Floor', 'GasA', 'GasW', 'Grav', 'OthW', 'Wall']], 'HeatingQC_Ex': ['HeatingQC', 'Ex', ['Ex', 'Fa', 'Gd', 'Po', 'TA']], 'HeatingQC_Fa': ['HeatingQC', 'Fa', ['Ex', 'Fa', 'Gd', 'Po', 'TA']], 'HeatingQC_Gd': ['HeatingQC', 'Gd', ['Ex', 'Fa', 'Gd', 'Po', 'TA']], 'HeatingQC_Po': ['HeatingQC', 'Po', ['Ex', 'Fa', 'Gd', 'Po', 'TA']], 'HeatingQC_TA': ['HeatingQC', 'TA', ['Ex', 'Fa', 'Gd', 'Po', 'TA']], 'PavedDrive_N': ['PavedDrive', 'N', ['N', 'P', 'Y']], 'PavedDrive_P': ['PavedDrive', 'P', ['N', 'P', 'Y']], 'PavedDrive_Y': ['PavedDrive', 'Y', ['N', 'P', 'Y']], 'SaleCondition_Abnorml': ['SaleCondition', 'Abnorml', ['Abnorml', 'AdjLand', 'Alloca', 'Family', 'Normal', 'Partial']], 'SaleCondition_AdjLand': ['SaleCondition', 'AdjLand', ['Abnorml', 'AdjLand', 'Alloca', 'Family', 'Normal', 'Partial']], 'SaleCondition_Alloca': ['SaleCondition', 'Alloca', ['Abnorml', 'AdjLand', 'Alloca', 'Family', 'Normal', 'Partial']], 'SaleCondition_Family': ['SaleCondition', 'Family', ['Abnorml', 'AdjLand', 'Alloca', 'Family', 'Normal', 'Partial']], 'SaleCondition_Normal': ['SaleCondition', 'Normal', ['Abnorml', 'AdjLand', 'Alloca', 'Family', 'Normal', 'Partial']], 'SaleCondition_Partial': ['SaleCondition', 'Partial', ['Abnorml', 'AdjLand', 'Alloca', 'Family', 'Normal', 'Partial']]}
Number of used features in the model (before the encoding): 44
Number of used features in the model (after the encoding): 153
----------------------------------------------
instance: [ 0 0 0 0 0 1 0 0 0 0 0 0 0 0
0 0 8450 1 0 0 0 1 0 0 0 1 0 0
0 0 1 1 0 0 0 0 0 0 0 1 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 1 0 0 0 0 0 0 0 0
1 0 0 0 0 0 1 0 0 0 0 0 0 0
0 0 1 0 0 0 0 0 0 0 0 1 0 0
0 0 0 0 0 1 0 0 0 0 2003 2003 0 1
0 0 0 0 0 1 0 0 0 0 0 0 0 0
1 0 0 0 0 0 1 0 0 1 0 0 0 0
1 0 0 0 0 1 0 0 0 0 1 856 854 0
1710 2 1 3 1 8 0 0 0 1 0 61 0 0
0 0 0 2 2008 0 0 0 0 1 0]
prediction: 199248.22
len binary representation: 1696
len direct: 413
is_reason: True
to_features: ('MSSubClass = 60', 'LotArea in [8159, 8592.5[', 'LotShape = Reg', 'LandContour = Lvl', 'LotConfig != {Corner,CulDSac,FR3,FR2}', 'LandSlope = Gtl', 'Neighborhood = CollgCr', 'Condition1 = Norm', 'Condition2 != Feedr', 'HouseStyle != {1.5Fin,1.5Unf,SFoyer}', 'OverallQual = 7', 'OverallCond = 5', 'YearBuilt in [2000, 2005.5[', 'YearRemodAdd in [1975.5, 2006.5[', 'RoofStyle = Gable', 'RoofMatl != {WdShngl,Tar&Grv}', 'ExterQual != {TA,Ex,Fa}', 'ExterCond = TA', 'Foundation = PConc', 'Heating = GasA', 'HeatingQC = Ex', 'CentralAir = 1', '1stFlrSF in [843, 868.5[', '2ndFlrSF in [841.5, 899.5[', 'LowQualFinSF < 114', 'GrLivArea in [1619, 1743.5[', 'FullBath in [0.5, 2.5[', 'BedroomAbvGr in [2.5, 5.5[', 'KitchenAbvGr in [0.5, 1.5[', 'TotRmsAbvGrd in [4.5, 9.5[', 'Fireplaces < 0.5', 'PavedDrive = Y', 'WoodDeckSF < 84.5', 'OpenPorchSF in [60.5, 62.5[', 'EnclosedPorch < 19', '3SsnPorch < 88', 'ScreenPorch < 32', 'PoolArea < 496', 'MiscVal < 467.5', 'MoSold in [1.5, 5.5[', 'YrSold in [2006.5, 2009.5[', 'SaleCondition != {Family,Abnorml,Partial}')
We can remark that the direct reason for this instance $x$ contains 413 binary variables of $t_{\vec x}$ out of 1696. This reason explains why the model predicts the regression value for this instance. But it is probably not the most compact reason for this instance, we invite you to look at the other types of reasons presented on the Boosted Tree Explanations page. More precisely, the Tree-Specific reasons are often more compact and therefore more interpretable reasons.