| |
| Data
Mining |
|
Data mining, also called knowledge discovery
in database (KDD), is the nontrivial extraction of implicit, previously
unknown, and potentially useful information from data in database.
There have been many advances on researches and developments of
data mining, and many data mining techniques and systems have
recently been developed. Data mining is finding increasing acceptance
in science and business areas which need to analyze large amounts
of data to discover trends which they could not otherwise find.
Data mining is the technique and applcation of the union of developments
in statistics, AI, and machine learning for data analysis and
finding previously-hidden trends or patterns within large amounts
of data.
Data mining techniques are the result of a long process of research
and development. This evolution began with data collection (1960s)
on computers, continued with improvements in data access(1980s),
and then Data Warehousing & Decision Support (1990s), and more
recently, generated technologies that allow users to automatically,
intelligently and rapidly manage data, analyze and extract implicit,
previously unknown interesting data patterns, relationships and
knowledge that hide within the data in real time. |
|
| |
|
| Data mining
tasks |
|
- Model Building : aim to build explicit models
- Classification
- Prediction
- Automatic Pattern Extraction : aim to automatically identify
useful patterns in data
- Cluster Analysis
- Association rule mining
- Interactive Visual Data Exploration: aim to simply help to
describe complex information and better understand what is going
on in the data
- visualization of data
- visual data exploration
|
|
| |
|
| Important
base of techniques |
|
Machine Learning
The one of the most important base of techniques for data mining
is machine learning, which is more accurately described as the
union of statistics and AI. Machine learning could be considered
an evolution of AI, because it blends AI heuristics with advanced
statistical analysis. Machine learning attempts to let computer
programs learn about the data they study, such that programs make
different decisions based on the qualities of the studied data,
using statistics for fundamental concepts, and adding more advanced
AI heuristics and algorithms to achieve its goals. Data mining,
in many ways, is fundamentally the adaptation of machine learning
techniques to business applications.
Many techniques are used in data mining :
- Fuzzy set
- Rough set
- Concept lattice
- Decision trees
- Genetic algorithms
- Bayesian network
- Nneural networks
- Nearest neighbor method
- SVM(Support Vector Machines)
- Bagging (Voting, Averaging)
- Boosting
- Rule induction
|
|
| |
|
| The processes
of Data mining and KDD |
|
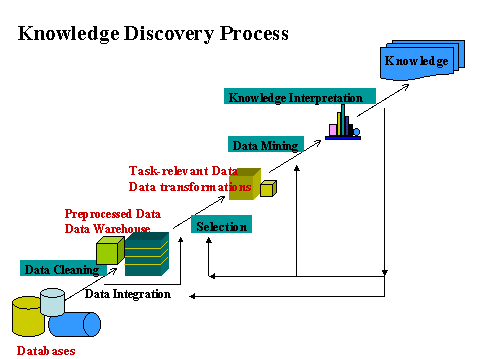
-
Preprocessing - this is the data cleansing
stage where certain information is removed which is deemed
unnecessary and may slow down queries for example unnecessary
to note the sex of a patient when studying pregnancy. Also
the data is reconfigured to ensure a consistent format as
there is a possibility of inconsistent formats because the
data is drawn from several sources e.g. sex may recorded as
f or m and also as 1 or 0.
- Selection - selecting or segmenting the data according to
some criteria
-
Transformation - the data is not merely
transferred across but transformed in that overlays may added
such as the demographic overlays commonly used in market research.
The data is made useable and navigable.
-
Data mining - extraction of patterns from
the data. This is core of KDD.
-
Interpretation and evaluation - the patterns
identified by the system are interpreted into knowledge which
can then be used to support human decision-making e.g. prediction
and classification tasks, summarizing the contents of a database
or explaining observed phenomena.
|
|
 |
|
| |
|
| References |
|
| [1] |
R. Cooley , B. Mobasher , J. Srivastava, Web
mining: Information and pattern discovery on the World Wide
Web, Proceedings of the International Conference on Tools
with Artificial Intelligence, 1997. |
| [2] |
Myra Spilioupulou, Laborious way from data mining to web
log mining, Computer Systems Science and Engineering, Vol.
14, No. 2, 1999, p113-125. |
| [3] |
Maurizio Cibelli, Gennaro Costagliola, Automatic generation
of Web mining environments, Proceedings of SPIE, The International
Society for Optical Engineering. Vol. 3695, 1999, p215-225.
|
| [4] |
Osmar R. Zaiane , Man Xin , Jiawei Han , Discovering web
access patterns and trends by applying OLAP and data mining
technology on web logs, Proceedings of the Forum on Research
and Technology Advances in Digital Libraries, ADL, 1998. |
| [5] |
Minos et al. Sequential pattern mining with regular expression
constraints. VLDB 1999. |
| [6] |
Rakesh Agrawal, Ramakrishnam Srikant, Mining sequential
patterns. ICDE 1995. |
| [7] |
T. Imielinski, A. Virmani, MSQL: A Query Language for Database
Mining, Data Mining and Knowledge Discovery, Vol. 3, 1999. |
| [8] |
J. Han. Data mining techniques. SIGMOD, 1996. |
| [9] |
M. Garofalakis, R. Rastogi, S. Seshadri, and K, Shim. Data
Mining and the Web: Past, Present, and Future |
| [10] |
Chaudhuri, Surajit, Umeshwar Dayal, "An Overview of
Data Warehousing and OLAP Technology". SIGMOD Record,
Vol. 26, No. 1, March 1997 |
| [11] |
H. Chipman, E. I. George, and R. E. McCulloch. Bayesian
CART model search (with discussion). Journal of the American
Statistical Association, 93:935-960, 1998. |
| [12] |
J. Han, Y. Cai, and N. Cercone, Knowledge Discovery in Databases:
An Attribute-Oriented Approach", VLDB-92, Vancouver,
British Columbia, Canada, 1992, 547-559. |
|
|
|
|