Lin Xu, Frank Hutter, Holger H. Hoos, Kevin Leyton-Brown
Department of Computer Science
University of British Columbia,
Vancouver, BC, Canada
In previous years, we submitted SATzilla as a solver to the SAT competition, showing that portfolio-based methods can often outperform their constituent solvers. Having established that point, we decided not to compete with solver authors in the SAT competition this year, to avoid discouraging new work on solvers. Instead, we entered SATzilla in the new "analysis track", which allows us to demonstrate SATzilla's performance while keeping the focus where it belongs: on the solvers inside the portfolio. This is important because in some cases, component solvers that make a big difference aren't strong solvers in the "winner take all" sense; analyzing the choices made by a solver like SATzilla can identify such contributions.
We constructed portfolios including all non-portfolio, non-parallel solvers from Phase 2 of the competition as component solvers, and compared them to the "virtual best solver" (VBS): an oracle that magically chooses the best solver for each instance and considers all competition entrants (including parallel solvers, solvers we discarded as being unhelpful to SATzilla, etc). The VBS does not represent the current state of the art, since it cannot be run on new instances; nevertheless, it serves as an upper bound on the performance that any portfolio-based selector could achieve. We also compared to the winners of each category (including other portfolio-based solvers). Note that our results can not be used to determine which portfolio building procedure (e.g., SATzilla, 3S, or ppfolio) is the best, since our SATzilla portfolios had access to data and solvers unavailable to portfolios that competed in the solver track. However, since we combine the most advanced SAT solvers using a tried-and-tested portfolio building procedure, we believe that the resulting portfolios represent or at least closely approximate the best performance reachable by currently available methods.
Results The table below shows the results of our analysis. We used the latest version of SATzilla (SATzilla 2011), trained on all non-portfolio, non-parallel solvers from Phase 2 of the competition and evaluated using 10-fold cross-validation on the complete instance set from the competition. (Cross-validation using an instance set S returns an unbiased estimate of how well SATzilla would do on new instances from the same distribution as S.) As can be seen from these results, SATzilla 2011 performed substantially better than the gold medalists (including other portfolio-based solvers), reducing the gap between these and the VBS by 27.7% on Application, by 53.2% on Crafted and 90.1% on Random.
| Category | Gold medal winner | SATzilla 2011 | Virtual best solver |
| Application | 71.7% (1856 CPU s) - Glucose 2 | 75.3% (1685 CPU s) | 84.7% (1104 CPU s) |
| Crafted | 54.3% (2602 CPU s) - 3S | 66.0% (2096 CPU s) | 76.3% (1542 CPU s) |
| Random | 68.0% (1836 CPU s) - 3S | 80.8% (1172 CPU s) | 82.2% (1074 CPU s) |
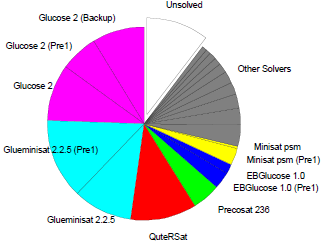
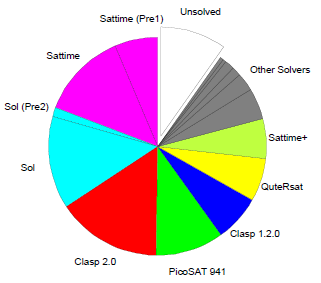
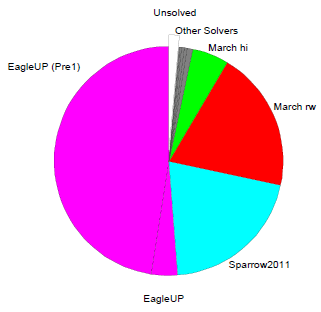
To evaluate how important each solver was for SATzilla, for each category we plot the percentage of instances solved by each solver during SATzilla's presolving (Pre1 or Pre2), backup, and main stages. Note that our use of cross-validation means that we constructed 10 different SATzilla portfolios using 10 different subsets ("folds") of instances. These 10 portfolios can be qualitatively different (e.g., selecting different presolvers); we report aggregates over the 10 folds.
| |
|
|
|
|
|
|
In our full results,
we also quantify the omission cost
of each
candidate solver from SATzilla, i.e., the reduction in the percentage of instances SATzilla was able to solve when the given solver was excluded. In a nutshell, we found the following. In the
Application category, every solver could be well substituted by others, with MPhaseSAT64 being
the only solver with omission cost over 1.5% (specifically, 1.6%). In the Crafted category, many
solvers were rather unique, with Sol having the highest omission cost (8.1%), and 5 other
solvers having omission cost over 1.5%: Sattime, MPhaseSAT and Glucose 2 (all 3.6%); Clasp 2.0 R2092 (2.7%), SApperloT2010 (1.8%). In the Random
category, two solvers had omission costs substantially larger than all others: Sparrow2011 (4.9%) and EagleUP (2.2%).
Acknowledgement. We thank Daniel Le Berre and Olivier Roussel for organizing this new track, for providing us with competition data and for running our feature computation code.